Kafka源码浅析
前言
本文阅读的Kafka源码版本为:kafka-3.0.0
生产者源码
生产者消息发送流程
在消息发送的过程中,涉及到了两个线程:main 线程和 Sender 线程。在 main 线程 中创建了一个双端队列 RecordAccumulator。main 线程通过分区器将消息发送给 RecordAccumulator, Sender 线程不断从 RecordAccumulator 中拉取消息发送到 Kafka Broker。
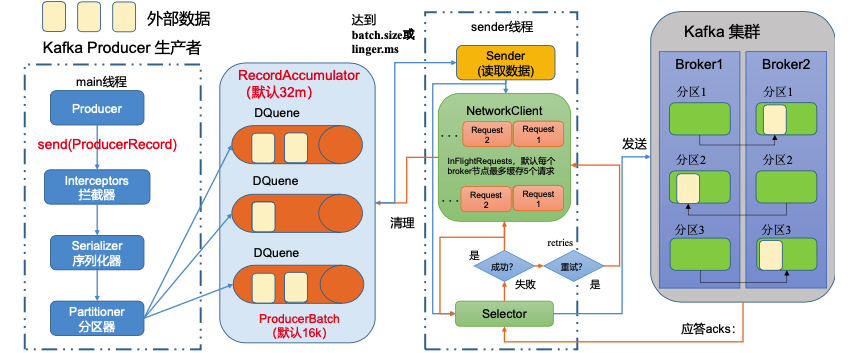
- batch.size:只有数据积累到batch.size之后,sender才会发送数据,默认16k
- linger.ms:如果数据迟迟未达到batch.size,sender等待linger.ms设置的时间。到了之后就会发送数据,单位ms,默认值是0ms,表示没有延迟。
应答acks:
- 0:生产者发送过来的数据,不需要等数据落盘应答。
- 1:生产者发送过来的数据,Leader 收到数据后应答。
- -1(all):生产者发送过来的数据,Leader 和 ISR 队列 里面的所有节点收齐数据后应答。-1和 all 等价。
初始化
生产者main线程初始化
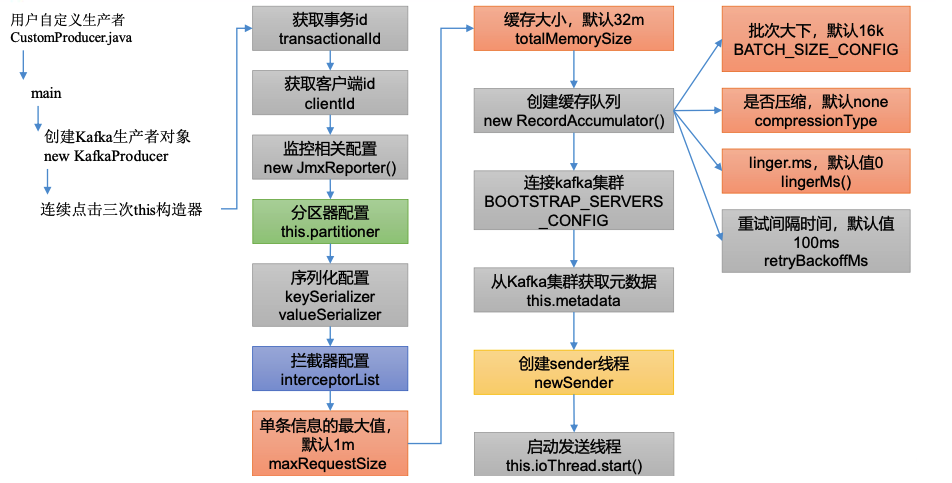
1)main线程中首先会通过构造器创建一个KafkaProducer()
public KafkaProducer(Properties properties) {
this(properties, null, null);
}
// 然后会依次调用以下构造器
public KafkaProducer(Properties properties, Serializer<K> keySerializer, Serializer<V> valueSerializer) {
this(Utils.propsToMap(properties), keySerializer, valueSerializer);
}
public KafkaProducer(Map<String, Object> configs, Serializer<K> keySerializer, Serializer<V> valueSerializer) {
this(new ProducerConfig(ProducerConfig.appendSerializerToConfig(configs, keySerializer, valueSerializer)),
keySerializer, valueSerializer, null, null, null, Time.SYSTEM);
}
2)最终调用的KafkaProducer构造器
@SuppressWarnings("unchecked")
KafkaProducer(ProducerConfig config,
Serializer<K> keySerializer,
Serializer<V> valueSerializer,
ProducerMetadata metadata,
KafkaClient kafkaClient,
ProducerInterceptors<K, V> interceptors,
Time time) {
try {
this.producerConfig = config;
this.time = time;
// 获取事务id
String transactionalId = config.getString(ProducerConfig.TRANSACTIONAL_ID_CONFIG);
// 获取客户端id
this.clientId = config.getString(ProducerConfig.CLIENT_ID_CONFIG);
LogContext logContext;
if (transactionalId == null)
logContext = new LogContext(String.format("[Producer clientId=%s] ", clientId));
else
logContext = new LogContext(String.format("[Producer clientId=%s, transactionalId=%s] ", clientId, transactionalId));
log = logContext.logger(KafkaProducer.class);
log.trace("Starting the Kafka producer");
Map<String, String> metricTags = Collections.singletonMap("client-id", clientId);
MetricConfig metricConfig = new MetricConfig().samples(config.getInt(ProducerConfig.METRICS_NUM_SAMPLES_CONFIG))
.timeWindow(config.getLong(ProducerConfig.METRICS_SAMPLE_WINDOW_MS_CONFIG), TimeUnit.MILLISECONDS)
.recordLevel(Sensor.RecordingLevel.forName(config.getString(ProducerConfig.METRICS_RECORDING_LEVEL_CONFIG)))
.tags(metricTags);
List<MetricsReporter> reporters = config.getConfiguredInstances(ProducerConfig.METRIC_REPORTER_CLASSES_CONFIG,
MetricsReporter.class,
Collections.singletonMap(ProducerConfig.CLIENT_ID_CONFIG, clientId));
// 监控kafka运行情况
JmxReporter jmxReporter = new JmxReporter();
jmxReporter.configure(config.originals(Collections.singletonMap(ProducerConfig.CLIENT_ID_CONFIG, clientId)));
reporters.add(jmxReporter);
MetricsContext metricsContext = new KafkaMetricsContext(JMX_PREFIX,
config.originalsWithPrefix(CommonClientConfigs.METRICS_CONTEXT_PREFIX));
this.metrics = new Metrics(metricConfig, reporters, time, metricsContext);
// 获取分区器
this.partitioner = config.getConfiguredInstance(
ProducerConfig.PARTITIONER_CLASS_CONFIG,
Partitioner.class,
Collections.singletonMap(ProducerConfig.CLIENT_ID_CONFIG, clientId));
// 重试时间间隔参数配置,默认值100ms
long retryBackoffMs = config.getLong(ProducerConfig.RETRY_BACKOFF_MS_CONFIG);
// key和value的序列化
if (keySerializer == null) {
this.keySerializer = config.getConfiguredInstance(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
Serializer.class);
this.keySerializer.configure(config.originals(Collections.singletonMap(ProducerConfig.CLIENT_ID_CONFIG, clientId)), true);
} else {
config.ignore(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG);
this.keySerializer = keySerializer;
}
if (valueSerializer == null) {
this.valueSerializer = config.getConfiguredInstance(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
Serializer.class);
this.valueSerializer.configure(config.originals(Collections.singletonMap(ProducerConfig.CLIENT_ID_CONFIG, clientId)), false);
} else {
config.ignore(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG);
this.valueSerializer = valueSerializer;
}
// 拦截器处理(拦截器可以有多个)
List<ProducerInterceptor<K, V>> interceptorList = (List) config.getConfiguredInstances(
ProducerConfig.INTERCEPTOR_CLASSES_CONFIG,
ProducerInterceptor.class,
Collections.singletonMap(ProducerConfig.CLIENT_ID_CONFIG, clientId));
if (interceptors != null)
this.interceptors = interceptors;
else
this.interceptors = new ProducerInterceptors<>(interceptorList);
ClusterResourceListeners clusterResourceListeners = configureClusterResourceListeners(keySerializer,
valueSerializer, interceptorList, reporters);
// 单条日志大小 默认1m
this.maxRequestSize = config.getInt(ProducerConfig.MAX_REQUEST_SIZE_CONFIG);
// 缓冲区大小 默认32m
this.totalMemorySize = config.getLong(ProducerConfig.BUFFER_MEMORY_CONFIG);
// 压缩,默认是none
this.compressionType = CompressionType.forName(config.getString(ProducerConfig.COMPRESSION_TYPE_CONFIG));
this.maxBlockTimeMs = config.getLong(ProducerConfig.MAX_BLOCK_MS_CONFIG);
int deliveryTimeoutMs = configureDeliveryTimeout(config, log);
this.apiVersions = new ApiVersions();
this.transactionManager = configureTransactionState(config, logContext);
// 缓冲区对象 默认是32m 参数列表如下:
// 批次大小 默认16k
// 压缩方式,默认是none
// liner.ms 默认是0
// 内存池
this.accumulator = new RecordAccumulator(logContext,
config.getInt(ProducerConfig.BATCH_SIZE_CONFIG),
this.compressionType,
lingerMs(config),
retryBackoffMs,
deliveryTimeoutMs,
metrics,
PRODUCER_METRIC_GROUP_NAME,
time,
apiVersions,
transactionManager,
new BufferPool(this.totalMemorySize, config.getInt(ProducerConfig.BATCH_SIZE_CONFIG), metrics, time, PRODUCER_METRIC_GROUP_NAME));
// 连接上kafka集群地址
List<InetSocketAddress> addresses = ClientUtils.parseAndValidateAddresses(
config.getList(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG),
config.getString(ProducerConfig.CLIENT_DNS_LOOKUP_CONFIG));
// 获取元数据
if (metadata != null) {
this.metadata = metadata;
} else {
this.metadata = new ProducerMetadata(retryBackoffMs,
config.getLong(ProducerConfig.METADATA_MAX_AGE_CONFIG),
config.getLong(ProducerConfig.METADATA_MAX_IDLE_CONFIG),
logContext,
clusterResourceListeners,
Time.SYSTEM);
this.metadata.bootstrap(addresses);
}
this.errors = this.metrics.sensor("errors");
this.sender = newSender(logContext, kafkaClient, this.metadata);
String ioThreadName = NETWORK_THREAD_PREFIX + " | " + clientId;
// 把sender线程放到后台
this.ioThread = new KafkaThread(ioThreadName, this.sender, true);
// ⭐️启动sender线程
this.ioThread.start();
config.logUnused();
AppInfoParser.registerAppInfo(JMX_PREFIX, clientId, metrics, time.milliseconds());
log.debug("Kafka producer started");
} catch (Throwable t) {
// call close methods if internal objects are already constructed this is to prevent resource leak. see KAFKA-2121
close(Duration.ofMillis(0), true);
// now propagate the exception
throw new KafkaException("Failed to construct kafka producer", t);
}
}
生产者sender线程初始化
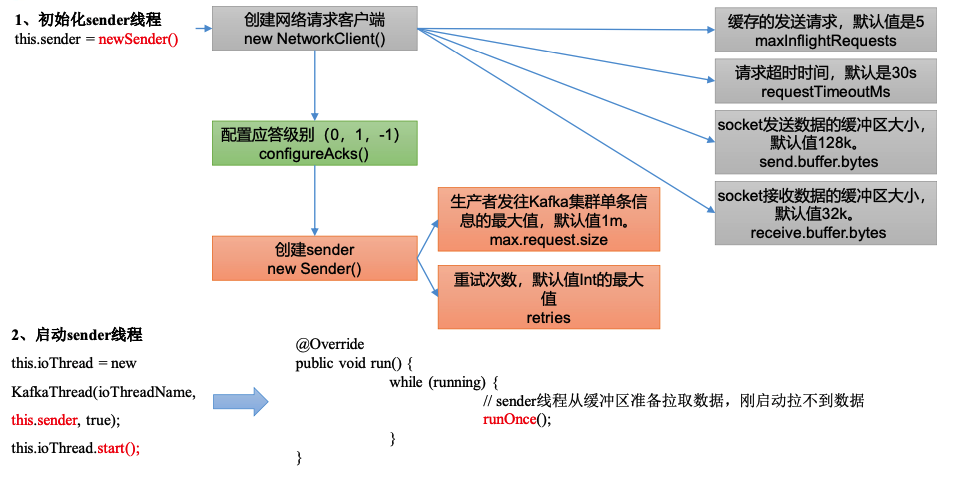
1)main线程初始化中,调用newSender(logContext, kafkaClient, this.metadata);来到sender线程初始化
Sender newSender(LogContext logContext, KafkaClient kafkaClient, ProducerMetadata metadata) {
// 缓存请求的个数 默认是5个
int maxInflightRequests = configureInflightRequests(producerConfig);
// 请求超时时间,默认30s
int requestTimeoutMs = producerConfig.getInt(ProducerConfig.REQUEST_TIMEOUT_MS_CONFIG);
ChannelBuilder channelBuilder = ClientUtils.createChannelBuilder(producerConfig, time, logContext);
ProducerMetrics metricsRegistry = new ProducerMetrics(this.metrics);
Sensor throttleTimeSensor = Sender.throttleTimeSensor(metricsRegistry.senderMetrics);
// 创建一个客户端对象
// clientId 客户端id
// maxInflightRequests 缓存请求的个数 默认是5个
// RECONNECT_BACKOFF_MS_CONFIG 重试时间
// RECONNECT_BACKOFF_MAX_MS_CONFIG 总的重试时间
// 发送缓冲区大小send.buffer.bytes 默认128kb
// 接收数据缓存 receive.buffer.bytes 默认是32kb
KafkaClient client = kafkaClient != null ? kafkaClient : new NetworkClient(
new Selector(producerConfig.getLong(ProducerConfig.CONNECTIONS_MAX_IDLE_MS_CONFIG),
this.metrics, time, "producer", channelBuilder, logContext),
metadata,
clientId,
maxInflightRequests,
producerConfig.getLong(ProducerConfig.RECONNECT_BACKOFF_MS_CONFIG),
producerConfig.getLong(ProducerConfig.RECONNECT_BACKOFF_MAX_MS_CONFIG),
producerConfig.getInt(ProducerConfig.SEND_BUFFER_CONFIG),
producerConfig.getInt(ProducerConfig.RECEIVE_BUFFER_CONFIG),
requestTimeoutMs,
producerConfig.getLong(ProducerConfig.SOCKET_CONNECTION_SETUP_TIMEOUT_MS_CONFIG),
producerConfig.getLong(ProducerConfig.SOCKET_CONNECTION_SETUP_TIMEOUT_MAX_MS_CONFIG),
time,
true,
apiVersions,
throttleTimeSensor,
logContext);
// 0 :生产者发送过来,不需要应答; 1 :leader收到,应答; -1 :leader和isr队列里面所有的都收到了应答
short acks = configureAcks(producerConfig, log);
// 创建sender线程
return new Sender(logContext,
client,
metadata,
this.accumulator,
maxInflightRequests == 1,
producerConfig.getInt(ProducerConfig.MAX_REQUEST_SIZE_CONFIG),
acks,
producerConfig.getInt(ProducerConfig.RETRIES_CONFIG),
metricsRegistry.senderMetrics,
time,
requestTimeoutMs,
producerConfig.getLong(ProducerConfig.RETRY_BACKOFF_MS_CONFIG),
this.transactionManager,
apiVersions);
}
2)Sender 对象被放到了一个线程中启动,所有需要点击 newSender()方法中的 Sender,并 找到 sender 对象中的 run()方法。
public void run() {
log.debug("Starting Kafka producer I/O thread.");
// main loop, runs until close is called
while (running) {
try {
// sender 线程从缓冲区准备拉取数据,刚启动拉不到数据
runOnce();
} catch (Exception e) {
log.error("Uncaught error in kafka producer I/O thread: ", e);
}
}
...
}
生产者发送数据到缓冲区
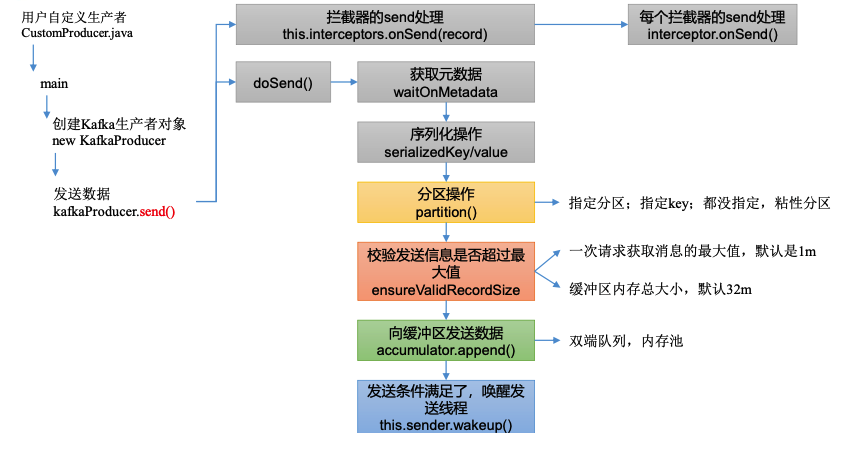
发送总体流程
1)KafkaProducer.send()方法
public Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback) {
// intercept the record, which can be potentially modified; this method does not throw exceptions
// 拦截器相关操作
ProducerRecord<K, V> interceptedRecord = this.interceptors.onSend(record);
return doSend(interceptedRecord, callback);
}
2)其中的 onSend()方法,进行拦截器相关处理。
public ProducerRecord<K, V> onSend(ProducerRecord<K, V> record) {
ProducerRecord<K, V> interceptRecord = record;
for (ProducerInterceptor<K, V> interceptor : this.interceptors) {
try {
// 拦截器对数据进行加工
interceptRecord = interceptor.onSend(interceptRecord);
} catch (Exception e) {
// do not propagate interceptor exception, log and continue calling other interceptors
// be careful not to throw exception from here
if (record != null)
log.warn("Error executing interceptor onSend callback for topic: {}, partition: {}", record.topic(), record.partition(), e);
else
log.warn("Error executing interceptor onSend callback", e);
}
}
return interceptRecord;
}
3)从拦截器处理中返回,点击 doSend()方法。
private Future<RecordMetadata> doSend(ProducerRecord<K, V> record, Callback callback) {
TopicPartition tp = null;
try {
throwIfProducerClosed();
// first make sure the metadata for the topic is available
long nowMs = time.milliseconds();
ClusterAndWaitTime clusterAndWaitTime;
try {
// 从 Kafka 拉取元数据。maxBlockTimeMs 表示最多能等待多长时间。
clusterAndWaitTime = waitOnMetadata(record.topic(), record.partition(), nowMs, maxBlockTimeMs);
} catch (KafkaException e) {
if (metadata.isClosed())
throw new KafkaException("Producer closed while send in progress", e);
throw e;
}
nowMs += clusterAndWaitTime.waitedOnMetadataMs;
// 剩余时间 = 最多能等待时间 - 用了多少时间;
long remainingWaitMs = Math.max(0, maxBlockTimeMs - clusterAndWaitTime.waitedOnMetadataMs);
// 更新集群元数据
Cluster cluster = clusterAndWaitTime.cluster;
// 序列化相关操作
byte[] serializedKey;
try {
serializedKey = keySerializer.serialize(record.topic(), record.headers(), record.key());
} catch (ClassCastException cce) {
throw new SerializationException("Can't convert key of class " + record.key().getClass().getName() +
" to class " + producerConfig.getClass(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG).getName() +
" specified in key.serializer", cce);
}
byte[] serializedValue;
try {
serializedValue = valueSerializer.serialize(record.topic(), record.headers(), record.value());
} catch (ClassCastException cce) {
throw new SerializationException("Can't convert value of class " + record.value().getClass().getName() +
" to class " + producerConfig.getClass(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG).getName() +
" specified in value.serializer", cce);
}
// 🤔分区操作(根据元数据信息)
int partition = partition(record, serializedKey, serializedValue, cluster);
tp = new TopicPartition(record.topic(), partition);
setReadOnly(record.headers());
Header[] headers = record.headers().toArray();
int serializedSize = AbstractRecords.estimateSizeInBytesUpperBound(apiVersions.maxUsableProduceMagic(),
compressionType, serializedKey, serializedValue, headers);
// 🤔保证数据大小能够传输(序列化后的 压缩后的),发送消息的大小是否超过最大值,默认是1m
ensureValidRecordSize(serializedSize);
long timestamp = record.timestamp() == null ? nowMs : record.timestamp();
if (log.isTraceEnabled()) {
log.trace("Attempting to append record {} with callback {} to topic {} partition {}", record, callback, record.topic(), partition);
}
// 消息发送的回调函数
// producer callback will make sure to call both 'callback' and interceptor callback
Callback interceptCallback = new InterceptorCallback<>(callback, this.interceptors, tp);
if (transactionManager != null && transactionManager.isTransactional()) {
transactionManager.failIfNotReadyForSend();
}
// 🤔accumulator缓存 追加数据 result是是否添加成功的结果
RecordAccumulator.RecordAppendResult result = accumulator.append(tp, timestamp, serializedKey,
serializedValue, headers, interceptCallback, remainingWaitMs, true, nowMs);
if (result.abortForNewBatch) {
int prevPartition = partition;
partitioner.onNewBatch(record.topic(), cluster, prevPartition);
partition = partition(record, serializedKey, serializedValue, cluster);
tp = new TopicPartition(record.topic(), partition);
if (log.isTraceEnabled()) {
log.trace("Retrying append due to new batch creation for topic {} partition {}. The old partition was {}", record.topic(), partition, prevPartition);
}
// producer callback will make sure to call both 'callback' and interceptor callback
interceptCallback = new InterceptorCallback<>(callback, this.interceptors, tp);
result = accumulator.append(tp, timestamp, serializedKey,
serializedValue, headers, interceptCallback, remainingWaitMs, false, nowMs);
}
if (transactionManager != null && transactionManager.isTransactional())
transactionManager.maybeAddPartitionToTransaction(tp);
// 批次大小已经满了 获取有一个新批次创建
if (result.batchIsFull || result.newBatchCreated) {
log.trace("Waking up the sender since topic {} partition {} is either full or getting a new batch", record.topic(), partition);
// 唤醒发送线程
this.sender.wakeup();
}
return result.future;
// handling exceptions and record the errors;
// for API exceptions return them in the future,
// for other exceptions throw directly
} catch (ApiException e) {
log.debug("Exception occurred during message send:", e);
if (callback != null)
callback.onCompletion(null, e);
this.errors.record();
this.interceptors.onSendError(record, tp, e);
return new FutureFailure(e);
} catch (InterruptedException e) {
this.errors.record();
this.interceptors.onSendError(record, tp, e);
throw new InterruptException(e);
} catch (KafkaException e) {
this.errors.record();
this.interceptors.onSendError(record, tp, e);
throw e;
} catch (Exception e) {
// we notify interceptor about all exceptions, since onSend is called before anything else in this method
this.interceptors.onSendError(record, tp, e);
throw e;
}
}
分区选择
1)发送总体流程中以下代码为分区选择相关流程:
// 分区操作
int partition = partition(record, serializedKey, serializedValue, cluster);
tp = new TopicPartition(record.topic(), partition);
// partition()方法具体如下:
private int partition(ProducerRecord<K, V> record, byte[] serializedKey, byte[] serializedValue, Cluster cluster) {
Integer partition = record.partition();
// 如果指定分区,按照指定分区配置
return partition != null ?
partition :
// 分区器选择分区
partitioner.partition( // 点击 partition,跳转到 Partitioner 接口,选择默认的分区器 DefaultPartitioner --> 2⃣️
record.topic(), record.key(), serializedKey, record.value(), serializedValue, cluster);
}
2)点击 partition,跳转到 Partitioner 接口,选择默认的分区器 DefaultPartitioner
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster,
int numPartitions) {
// 没有指定key
if (keyBytes == null) {
// 按照粘性分区处理 --> 3⃣️
return stickyPartitionCache.partition(topic, cluster);
}
// 如果指定key,按照key的hashcode值 对分区数求模
// hash the keyBytes to choose a partition
return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}
---------------------------------------------------------
// 3⃣️没有指定key和分区的处理方式 stickyPartitionCache.partition(topic, cluster);
public int partition(String topic, Cluster cluster) {
Integer part = indexCache.get(topic);
if (part == null) {
return nextPartition(topic, cluster, -1); // --> 4⃣️
}
return part;
}
---------------------------------------------------------
// 4⃣️nextPartition(topic, cluster, -1);
public int nextPartition(String topic, Cluster cluster, int prevPartition) {
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
Integer oldPart = indexCache.get(topic);
Integer newPart = oldPart;
// Check that the current sticky partition for the topic is either not set or that the partition that
// triggered the new batch matches the sticky partition that needs to be changed.
if (oldPart == null || oldPart == prevPartition) {
List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic);
if (availablePartitions.size() < 1) {
Integer random = Utils.toPositive(ThreadLocalRandom.current().nextInt());
newPart = random % partitions.size();
} else if (availablePartitions.size() == 1) {
newPart = availablePartitions.get(0).partition();
} else {
while (newPart == null || newPart.equals(oldPart)) {
int random = Utils.toPositive(ThreadLocalRandom.current().nextInt());
newPart = availablePartitions.get(random % availablePartitions.size()).partition();
}
}
// Only change the sticky partition if it is null or prevPartition matches the current sticky partition.
if (oldPart == null) {
indexCache.putIfAbsent(topic, newPart);
} else {
indexCache.replace(topic, prevPartition, newPart);
}
return indexCache.get(topic);
}
return indexCache.get(topic);
}
发送消息大小校验
发送总体流程中的ensureValidRecordSize(serializedSize)方法涉及到发送消息大小校验操作
private void ensureValidRecordSize(int size) {
// 单条信息最大值 maxRequestSize 1m
if (size > maxRequestSize)
throw new RecordTooLargeException("The message is " + size +
" bytes when serialized which is larger than " + maxRequestSize + ", which is the value of the " +
ProducerConfig.MAX_REQUEST_SIZE_CONFIG + " configuration.");
// 缓冲区内存总大小,默认32m
if (size > totalMemorySize)
throw new RecordTooLargeException("The message is " + size +
" bytes when serialized which is larger than the total memory buffer you have configured with the " +
ProducerConfig.BUFFER_MEMORY_CONFIG +
" configuration.");
}
内存/缓存池
发送总体流程中的RecordAccumulator.RecordAppendResult result = accumulator.append(...);
public RecordAppendResult append(TopicPartition tp,
long timestamp,
byte[] key,
byte[] value,
Header[] headers,
Callback callback,
long maxTimeToBlock,
boolean abortOnNewBatch,
long nowMs) throws InterruptedException {
// We keep track of the number of appending thread to make sure we do not miss batches in
// abortIncompleteBatches().
appendsInProgress.incrementAndGet();
ByteBuffer buffer = null;
if (headers == null) headers = Record.EMPTY_HEADERS;
try {
// check if we have an in-progress batch
// 获取或者创建一个队列(按照每个主题的分区)
Deque<ProducerBatch> dq = getOrCreateDeque(tp);
synchronized (dq) {
if (closed)
throw new KafkaException("Producer closed while send in progress");
// 尝试向队列里面添加数据(没有分配内存、批次对象,所以失败)
RecordAppendResult appendResult = tryAppend(timestamp, key, value, headers, callback, dq, nowMs);
if (appendResult != null)
return appendResult;
}
// we don't have an in-progress record batch try to allocate a new batch
if (abortOnNewBatch) {
// Return a result that will cause another call to append.
return new RecordAppendResult(null, false, false, true);
}
byte maxUsableMagic = apiVersions.maxUsableProduceMagic();
// this.batchSize 默认16k 数据大小17k
int size = Math.max(this.batchSize, AbstractRecords.estimateSizeInBytesUpperBound(maxUsableMagic, compression, key, value, headers));
log.trace("Allocating a new {} byte message buffer for topic {} partition {} with remaining timeout {}ms", size, tp.topic(), tp.partition(), maxTimeToBlock);
// 申请内存 内存池根据批次大小(默认16k)和消息大小中最大值,分配内存 😎双端队列
buffer = free.allocate(size, maxTimeToBlock);
// Update the current time in case the buffer allocation blocked above.
nowMs = time.milliseconds();
synchronized (dq) {
// Need to check if producer is closed again after grabbing the dequeue lock.
if (closed)
throw new KafkaException("Producer closed while send in progress");
// 尝试向队列里面添加数据(有内存,但是没有批次对象)
RecordAppendResult appendResult = tryAppend(timestamp, key, value, headers, callback, dq, nowMs);
if (appendResult != null) {
// Somebody else found us a batch, return the one we waited for! Hopefully this doesn't happen often...
return appendResult;
}
// 封装内存buffer
MemoryRecordsBuilder recordsBuilder = recordsBuilder(buffer, maxUsableMagic);
// 根据内存大小封装批次(有内存、有批次对象)
ProducerBatch batch = new ProducerBatch(tp, recordsBuilder, nowMs);
// 尝试向队列里面添加数据
FutureRecordMetadata future = Objects.requireNonNull(batch.tryAppend(timestamp, key, value, headers,
callback, nowMs));
// 把新创建的批次放到队列末尾
dq.addLast(batch);
incomplete.add(batch);
// Don't deallocate this buffer in the finally block as it's being used in the record batch
buffer = null;
return new RecordAppendResult(future, dq.size() > 1 || batch.isFull(), true, false);
}
} finally {
// 如果发生异常,释放内存
if (buffer != null)
free.deallocate(buffer);
appendsInProgress.decrementAndGet();
}
}
sender 线程发送数据
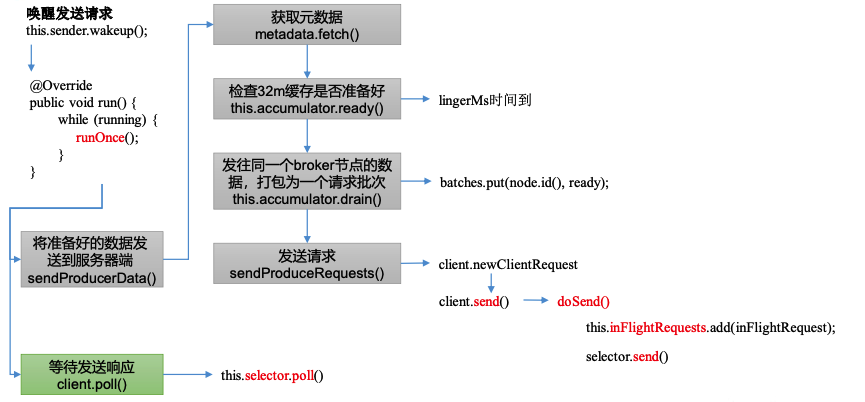
1)进入 sender 发送线程的 run()方法。
public void run() {
log.debug("Starting Kafka producer I/O thread.");
// main loop, runs until close is called
while (running) {
try {
// sender 线程从缓冲区准备拉取数据,刚启动拉不到数据 --> 2⃣️
runOnce();
} catch (Exception e) {
log.error("Uncaught error in kafka producer I/O thread: ", e);
}
}
...
}
2)runOnce()方法
void runOnce() {
// 如果是事务操作,按照如下处理
if (transactionManager != null) {
try {
transactionManager.maybeResolveSequences();
// do not continue sending if the transaction manager is in a failed state
if (transactionManager.hasFatalError()) {
RuntimeException lastError = transactionManager.lastError();
if (lastError != null)
maybeAbortBatches(lastError);
// 获取服务器端响应 -->7⃣️
client.poll(retryBackoffMs, time.milliseconds());
return;
}
// Check whether we need a new producerId. If so, we will enqueue an InitProducerId
// request which will be sent below
transactionManager.bumpIdempotentEpochAndResetIdIfNeeded();
if (maybeSendAndPollTransactionalRequest()) {
return;
}
} catch (AuthenticationException e) {
// This is already logged as error, but propagated here to perform any clean ups.
log.trace("Authentication exception while processing transactional request", e);
transactionManager.authenticationFailed(e);
}
}
long currentTimeMs = time.milliseconds();
// 将准备好的数据发送到服务器端 --> 3⃣️
long pollTimeout = sendProducerData(currentTimeMs);
// 获取发送结果
client.poll(pollTimeout, currentTimeMs);
}
3)获取要发送数据的细节 sendProducerData()
private long sendProducerData(long now) {
// 获取元数据
Cluster cluster = metadata.fetch();
// get the list of partitions with data ready to send
// 判断32m缓存是否准备好(linger.ms) --> 4⃣️
RecordAccumulator.ReadyCheckResult result = this.accumulator.ready(cluster, now);
// 如果Leader信息不知道,是不能发送数据的
// if there are any partitions whose leaders are not known yet, force metadata update
if (!result.unknownLeaderTopics.isEmpty()) {
// The set of topics with unknown leader contains topics with leader election pending as well as
// topics which may have expired. Add the topic again to metadata to ensure it is included
// and request metadata update, since there are messages to send to the topic.
for (String topic : result.unknownLeaderTopics)
this.metadata.add(topic, now);
log.debug("Requesting metadata update due to unknown leader topics from the batched records: {}",
result.unknownLeaderTopics);
this.metadata.requestUpdate();
}
// remove any nodes we aren't ready to send to
// 删除掉没有准备好发送的数据
Iterator<Node> iter = result.readyNodes.iterator();
long notReadyTimeout = Long.MAX_VALUE;
while (iter.hasNext()) {
Node node = iter.next();
if (!this.client.ready(node, now)) {
iter.remove();
notReadyTimeout = Math.min(notReadyTimeout, this.client.pollDelayMs(node, now));
}
}
// create produce requests
// 发往同一个 broker 节点的数据,打包为一个请求批次 --> 5⃣️
Map<Integer, List<ProducerBatch>> batches = this.accumulator.drain(cluster, result.readyNodes, this.maxRequestSize, now);
addToInflightBatches(batches);
if (guaranteeMessageOrder) {
// Mute all the partitions drained
for (List<ProducerBatch> batchList : batches.values()) {
for (ProducerBatch batch : batchList)
this.accumulator.mutePartition(batch.topicPartition);
}
}
accumulator.resetNextBatchExpiryTime();
List<ProducerBatch> expiredInflightBatches = getExpiredInflightBatches(now);
List<ProducerBatch> expiredBatches = this.accumulator.expiredBatches(now);
expiredBatches.addAll(expiredInflightBatches);
// Reset the producer id if an expired batch has previously been sent to the broker. Also update the metrics
// for expired batches. see the documentation of @TransactionState.resetIdempotentProducerId to understand why
// we need to reset the producer id here.
if (!expiredBatches.isEmpty())
log.trace("Expired {} batches in accumulator", expiredBatches.size());
for (ProducerBatch expiredBatch : expiredBatches) {
String errorMessage = "Expiring " + expiredBatch.recordCount + " record(s) for " + expiredBatch.topicPartition
+ ":" + (now - expiredBatch.createdMs) + " ms has passed since batch creation";
failBatch(expiredBatch, new TimeoutException(errorMessage), false);
if (transactionManager != null && expiredBatch.inRetry()) {
// This ensures that no new batches are drained until the current in flight batches are fully resolved.
transactionManager.markSequenceUnresolved(expiredBatch);
}
}
sensors.updateProduceRequestMetrics(batches);
// If we have any nodes that are ready to send + have sendable data, poll with 0 timeout so this can immediately
// loop and try sending more data. Otherwise, the timeout will be the smaller value between next batch expiry
// time, and the delay time for checking data availability. Note that the nodes may have data that isn't yet
// sendable due to lingering, backing off, etc. This specifically does not include nodes with sendable data
// that aren't ready to send since they would cause busy looping.
long pollTimeout = Math.min(result.nextReadyCheckDelayMs, notReadyTimeout);
pollTimeout = Math.min(pollTimeout, this.accumulator.nextExpiryTimeMs() - now);
pollTimeout = Math.max(pollTimeout, 0);
if (!result.readyNodes.isEmpty()) {
log.trace("Nodes with data ready to send: {}", result.readyNodes);
// if some partitions are already ready to be sent, the select time would be 0;
// otherwise if some partition already has some data accumulated but not ready yet,
// the select time will be the time difference between now and its linger expiry time;
// otherwise the select time will be the time difference between now and the metadata expiry time;
pollTimeout = 0;
}
// 发送请求 --> 6⃣️
sendProduceRequests(batches, now);
return pollTimeout;
}
4)判断32m缓存是否准备好
public ReadyCheckResult ready(Cluster cluster, long nowMs) {
Set<Node> readyNodes = new HashSet<>();
long nextReadyCheckDelayMs = Long.MAX_VALUE;
Set<String> unknownLeaderTopics = new HashSet<>();
boolean exhausted = this.free.queued() > 0;
for (Map.Entry<TopicPartition, Deque<ProducerBatch>> entry : this.batches.entrySet()) {
Deque<ProducerBatch> deque = entry.getValue();
synchronized (deque) {
// When producing to a large number of partitions, this path is hot and deques are often empty.
// We check whether a batch exists first to avoid the more expensive checks whenever possible.
ProducerBatch batch = deque.peekFirst();
if (batch != null) {
TopicPartition part = entry.getKey();
Node leader = cluster.leaderFor(part);
if (leader == null) {
// This is a partition for which leader is not known, but messages are available to send.
// Note that entries are currently not removed from batches when deque is empty.
unknownLeaderTopics.add(part.topic());
} else if (!readyNodes.contains(leader) && !isMuted(part)) {
long waitedTimeMs = batch.waitedTimeMs(nowMs);
// 如果不是第一次拉取, 且等待时间小于重试时间 默认100ms ,backingOff=true
boolean backingOff = batch.attempts() > 0 && waitedTimeMs < retryBackoffMs;
// 如果backingOff是true 取retryBackoffMs; 如果不是第一次拉取取lingerMs,默认0
long timeToWaitMs = backingOff ? retryBackoffMs : lingerMs;
// 批次大小满足发送条件
boolean full = deque.size() > 1 || batch.isFull();
// 如果等待的时间超过了 timeToWaitMs,expired=true,表示可以发送数据
boolean expired = waitedTimeMs >= timeToWaitMs;
boolean transactionCompleting = transactionManager != null && transactionManager.isCompleting();
// full linger.ms
boolean sendable = full
|| expired
|| exhausted
|| closed
|| flushInProgress()
|| transactionCompleting;
if (sendable && !backingOff) {
readyNodes.add(leader);
} else {
long timeLeftMs = Math.max(timeToWaitMs - waitedTimeMs, 0);
// Note that this results in a conservative estimate since an un-sendable partition may have
// a leader that will later be found to have sendable data. However, this is good enough
// since we'll just wake up and then sleep again for the remaining time.
nextReadyCheckDelayMs = Math.min(timeLeftMs, nextReadyCheckDelayMs);
}
}
}
}
}
return new ReadyCheckResult(readyNodes, nextReadyCheckDelayMs, unknownLeaderTopics);
}
5)发往同一个 broker 节点的数据,打包为一个请求批次。
public Map<Integer, List<ProducerBatch>> drain(Cluster cluster, Set<Node> nodes, int maxSize, long now) {
if (nodes.isEmpty())
return Collections.emptyMap();
Map<Integer, List<ProducerBatch>> batches = new HashMap<>();
for (Node node : nodes) {
List<ProducerBatch> ready = drainBatchesForOneNode(cluster, node, maxSize, now);
batches.put(node.id(), ready);
}
return batches;
}
6)发送请求
private void sendProduceRequest(long now, int destination, short acks, int timeout, List<ProducerBatch> batches) {
if (batches.isEmpty())
return;
final Map<TopicPartition, ProducerBatch> recordsByPartition = new HashMap<>(batches.size());
// find the minimum magic version used when creating the record sets
byte minUsedMagic = apiVersions.maxUsableProduceMagic();
for (ProducerBatch batch : batches) {
if (batch.magic() < minUsedMagic)
minUsedMagic = batch.magic();
}
ProduceRequestData.TopicProduceDataCollection tpd = new ProduceRequestData.TopicProduceDataCollection();
for (ProducerBatch batch : batches) {
TopicPartition tp = batch.topicPartition;
MemoryRecords records = batch.records();
// down convert if necessary to the minimum magic used. In general, there can be a delay between the time
// that the producer starts building the batch and the time that we send the request, and we may have
// chosen the message format based on out-dated metadata. In the worst case, we optimistically chose to use
// the new message format, but found that the broker didn't support it, so we need to down-convert on the
// client before sending. This is intended to handle edge cases around cluster upgrades where brokers may
// not all support the same message format version. For example, if a partition migrates from a broker
// which is supporting the new magic version to one which doesn't, then we will need to convert.
if (!records.hasMatchingMagic(minUsedMagic))
records = batch.records().downConvert(minUsedMagic, 0, time).records();
ProduceRequestData.TopicProduceData tpData = tpd.find(tp.topic());
if (tpData == null) {
tpData = new ProduceRequestData.TopicProduceData().setName(tp.topic());
tpd.add(tpData);
}
tpData.partitionData().add(new ProduceRequestData.PartitionProduceData()
.setIndex(tp.partition())
.setRecords(records));
recordsByPartition.put(tp, batch);
}
String transactionalId = null;
if (transactionManager != null && transactionManager.isTransactional()) {
transactionalId = transactionManager.transactionalId();
}
ProduceRequest.Builder requestBuilder = ProduceRequest.forMagic(minUsedMagic,
new ProduceRequestData()
.setAcks(acks)
.setTimeoutMs(timeout)
.setTransactionalId(transactionalId)
.setTopicData(tpd));
RequestCompletionHandler callback = response -> handleProduceResponse(response, recordsByPartition, time.milliseconds());
String nodeId = Integer.toString(destination);
// 创建发送请求对象
ClientRequest clientRequest = client.newClientRequest(nodeId, requestBuilder, now, acks != 0,
requestTimeoutMs, callback);
// 发送请求
client.send(clientRequest, now);
log.trace("Sent produce request to {}: {}", nodeId, requestBuilder);
}
---------------------------------------------------------
public void send(ClientRequest request, long now) {
doSend(request, false, now);
}
---------------------------------------------------------
private void doSend(ClientRequest clientRequest, boolean isInternalRequest, long now, AbstractRequest request) {
String destination = clientRequest.destination();
RequestHeader header = clientRequest.makeHeader(request.version());
if (log.isDebugEnabled()) {
log.debug("Sending {} request with header {} and timeout {} to node {}: {}",
clientRequest.apiKey(), header, clientRequest.requestTimeoutMs(), destination, request);
}
Send send = request.toSend(header);
InFlightRequest inFlightRequest = new InFlightRequest(
clientRequest,
header,
isInternalRequest,
request,
send,
now);
// 添加请求到inflint
this.inFlightRequests.add(inFlightRequest);
// 发送数据
selector.send(new NetworkSend(clientRequest.destination(), send));
}
7)获取服务器端响应
public List<ClientResponse> poll(long timeout, long now) {
ensureActive();
if (!abortedSends.isEmpty()) {
// If there are aborted sends because of unsupported version exceptions or disconnects,
// handle them immediately without waiting for Selector#poll.
List<ClientResponse> responses = new ArrayList<>();
handleAbortedSends(responses);
completeResponses(responses);
return responses;
}
long metadataTimeout = metadataUpdater.maybeUpdate(now);
try {
this.selector.poll(Utils.min(timeout, metadataTimeout, defaultRequestTimeoutMs));
} catch (IOException e) {
log.error("Unexpected error during I/O", e);
}
// process completed actions
// 获取发送后的响应
long updatedNow = this.time.milliseconds();
List<ClientResponse> responses = new ArrayList<>();
handleCompletedSends(responses, updatedNow);
handleCompletedReceives(responses, updatedNow);
handleDisconnections(responses, updatedNow);
handleConnections();
handleInitiateApiVersionRequests(updatedNow);
handleTimedOutConnections(responses, updatedNow);
handleTimedOutRequests(responses, updatedNow);
completeResponses(responses);
return responses;
}
消费者源码
1)消费者组初始化流程
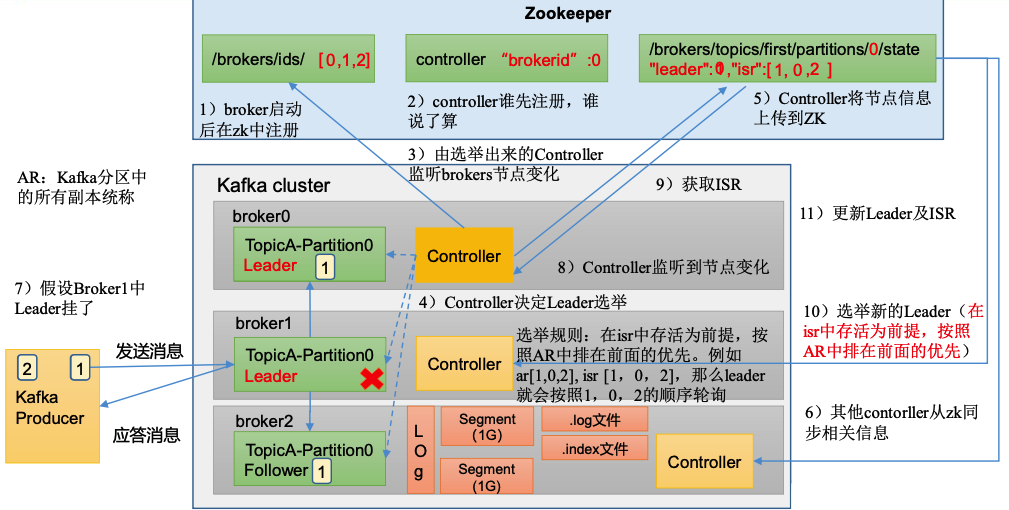
coordinator:辅助实现消费者组的初始化和分区的分配。
- coordinator节点选择=groupid的nashcode值%50(_consumer_offsets的分区数量)_
- 例如:groupid的hashcodef值=1,1%50=1,那么_consumer_offsets主题的1号分区,在哪个broker上,就选择这个节点的coordinator 作为这个消费者组的老大。消费者组下的所有的消费者提交offset的时候就往这个分区去提交offset。
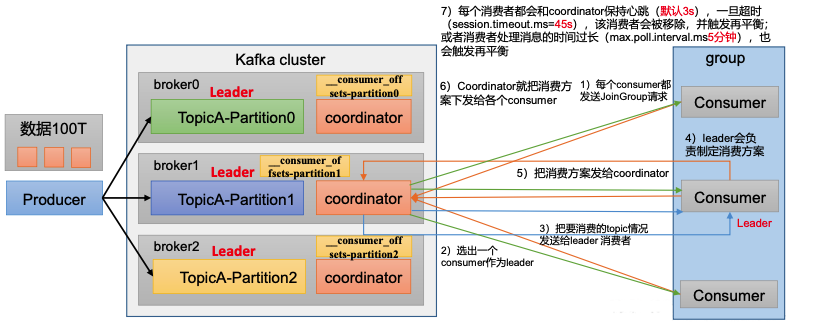
⚠️触发再平衡的两个条件:
- 每个消费者都会和coordinator保持心跳(默认3s),一旦超时 (session.timeout.ms=45s),该消费者会被移除,并触发再平衡;
- 或者消费者处理消息的时间过长(超过max.poll.interval.ms5分钟),也会触发再平衡
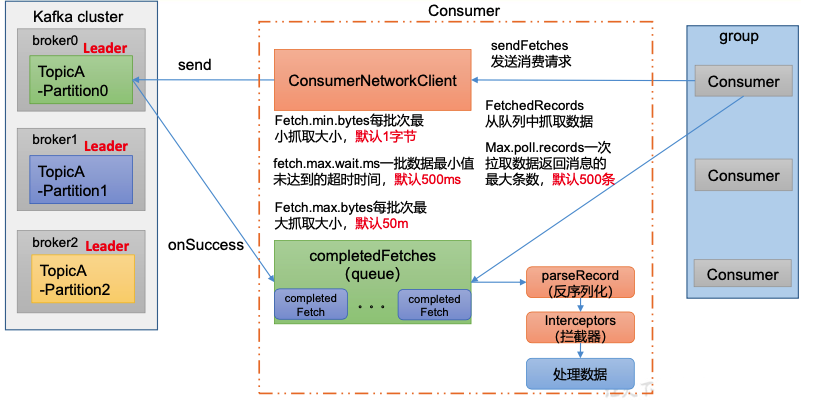
2)消费流程
- 创建COnsumerNetworkClient,接收消费者的消费请求sendFetches
- ConsumerNetworkClient通过send方法拉去broker中的消息,broker也有相应onSuccess回调方法
- 把拉去的消息放入completedFetches队列,消费者会按批次拉取数据
- 反序列化/拦截器/处理数据
消费者初始化
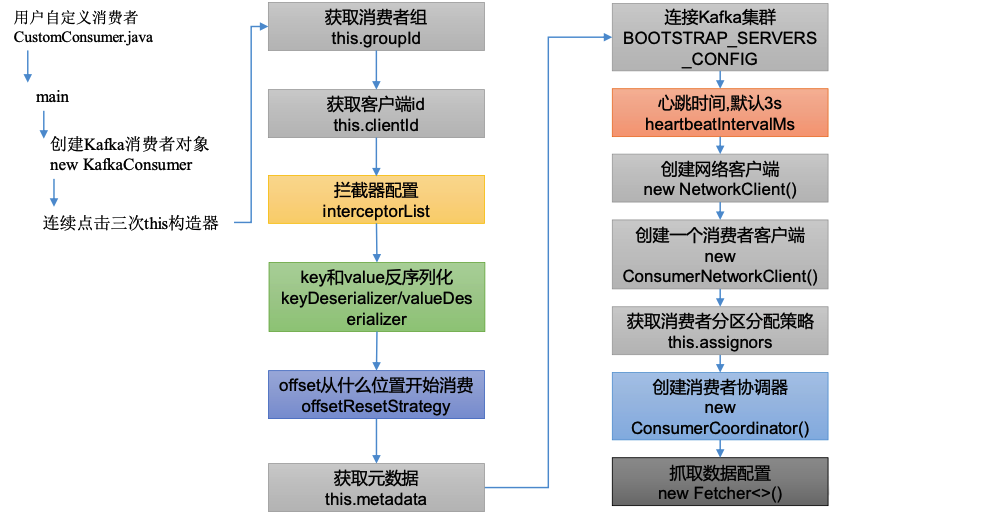
1) 查看KafkaConsumer 构造方法
KafkaConsumer(ConsumerConfig config, Deserializer<K> keyDeserializer, Deserializer<V> valueDeserializer) {
try {
// 消费组平衡
GroupRebalanceConfig groupRebalanceConfig = new GroupRebalanceConfig(config,
GroupRebalanceConfig.ProtocolType.CONSUMER);
// 获取消费者组id
this.groupId = Optional.ofNullable(groupRebalanceConfig.groupId);
// 客户端id
this.clientId = config.getString(CommonClientConfigs.CLIENT_ID_CONFIG);
LogContext logContext;
// If group.instance.id is set, we will append it to the log context.
if (groupRebalanceConfig.groupInstanceId.isPresent()) {
logContext = new LogContext("[Consumer instanceId=" + groupRebalanceConfig.groupInstanceId.get() +
", clientId=" + clientId + ", groupId=" + groupId.orElse("null") + "] ");
} else {
logContext = new LogContext("[Consumer clientId=" + clientId + ", groupId=" + groupId.orElse("null") + "] ");
}
this.log = logContext.logger(getClass());
boolean enableAutoCommit = config.maybeOverrideEnableAutoCommit();
groupId.ifPresent(groupIdStr -> {
if (groupIdStr.isEmpty()) {
log.warn("Support for using the empty group id by consumers is deprecated and will be removed in the next major release.");
}
});
log.debug("Initializing the Kafka consumer");
// 客户端请求服务端等待时间request.timeout.ms 默认是30s
this.requestTimeoutMs = config.getInt(ConsumerConfig.REQUEST_TIMEOUT_MS_CONFIG);
this.defaultApiTimeoutMs = config.getInt(ConsumerConfig.DEFAULT_API_TIMEOUT_MS_CONFIG);
this.time = Time.SYSTEM;
this.metrics = buildMetrics(config, time, clientId);
// 重试时间 100
this.retryBackoffMs = config.getLong(ConsumerConfig.RETRY_BACKOFF_MS_CONFIG);
// 拦截器配置
List<ConsumerInterceptor<K, V>> interceptorList = (List) config.getConfiguredInstances(
ConsumerConfig.INTERCEPTOR_CLASSES_CONFIG,
ConsumerInterceptor.class,
Collections.singletonMap(ConsumerConfig.CLIENT_ID_CONFIG, clientId));
this.interceptors = new ConsumerInterceptors<>(interceptorList);
// key和value 的反序列化
if (keyDeserializer == null) {
this.keyDeserializer = config.getConfiguredInstance(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, Deserializer.class);
this.keyDeserializer.configure(config.originals(Collections.singletonMap(ConsumerConfig.CLIENT_ID_CONFIG, clientId)), true);
} else {
config.ignore(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG);
this.keyDeserializer = keyDeserializer;
}
if (valueDeserializer == null) {
this.valueDeserializer = config.getConfiguredInstance(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, Deserializer.class);
this.valueDeserializer.configure(config.originals(Collections.singletonMap(ConsumerConfig.CLIENT_ID_CONFIG, clientId)), false);
} else {
config.ignore(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG);
this.valueDeserializer = valueDeserializer;
}
// offset从什么位置开始消费 默认,latest
OffsetResetStrategy offsetResetStrategy = OffsetResetStrategy.valueOf(config.getString(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG).toUpperCase(Locale.ROOT));
this.subscriptions = new SubscriptionState(logContext, offsetResetStrategy);
ClusterResourceListeners clusterResourceListeners = configureClusterResourceListeners(keyDeserializer,
valueDeserializer, metrics.reporters(), interceptorList);
// 元数据
// retryBackoffMs 重试时间
// 是否允许访问系统主题 exclude.internal.topics 默认是true,表示不允许
// 是否允许自动创建topic allow.auto.create.topics 默认是true
this.metadata = new ConsumerMetadata(retryBackoffMs,
config.getLong(ConsumerConfig.METADATA_MAX_AGE_CONFIG),
!config.getBoolean(ConsumerConfig.EXCLUDE_INTERNAL_TOPICS_CONFIG),
config.getBoolean(ConsumerConfig.ALLOW_AUTO_CREATE_TOPICS_CONFIG),
subscriptions, logContext, clusterResourceListeners);
// 连接kafka集群
List<InetSocketAddress> addresses = ClientUtils.parseAndValidateAddresses(
config.getList(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG), config.getString(ConsumerConfig.CLIENT_DNS_LOOKUP_CONFIG));
this.metadata.bootstrap(addresses);
String metricGrpPrefix = "consumer";
FetcherMetricsRegistry metricsRegistry = new FetcherMetricsRegistry(Collections.singleton(CLIENT_ID_METRIC_TAG), metricGrpPrefix);
ChannelBuilder channelBuilder = ClientUtils.createChannelBuilder(config, time, logContext);
this.isolationLevel = IsolationLevel.valueOf(
config.getString(ConsumerConfig.ISOLATION_LEVEL_CONFIG).toUpperCase(Locale.ROOT));
Sensor throttleTimeSensor = Fetcher.throttleTimeSensor(metrics, metricsRegistry);
// 心跳时间,默认3s
int heartbeatIntervalMs = config.getInt(ConsumerConfig.HEARTBEAT_INTERVAL_MS_CONFIG);
ApiVersions apiVersions = new ApiVersions();
// 创建客户端对象
// 连接重试时间 默认50ms
// 最大连接重试时间 默认1s
// 发送缓存 默认128kb
// 接收缓存 默认64kb
// 客户端请求服务端等待时间request.timeout.ms 默认是30s
NetworkClient netClient = new NetworkClient(
new Selector(config.getLong(ConsumerConfig.CONNECTIONS_MAX_IDLE_MS_CONFIG), metrics, time, metricGrpPrefix, channelBuilder, logContext),
this.metadata,
clientId,
100, // a fixed large enough value will suffice for max in-flight requests
config.getLong(ConsumerConfig.RECONNECT_BACKOFF_MS_CONFIG),
config.getLong(ConsumerConfig.RECONNECT_BACKOFF_MAX_MS_CONFIG),
config.getInt(ConsumerConfig.SEND_BUFFER_CONFIG),
config.getInt(ConsumerConfig.RECEIVE_BUFFER_CONFIG),
config.getInt(ConsumerConfig.REQUEST_TIMEOUT_MS_CONFIG),
config.getLong(ConsumerConfig.SOCKET_CONNECTION_SETUP_TIMEOUT_MS_CONFIG),
config.getLong(ConsumerConfig.SOCKET_CONNECTION_SETUP_TIMEOUT_MAX_MS_CONFIG),
time,
true,
apiVersions,
throttleTimeSensor,
logContext);
// 消费者客户端
// 客户端请求服务端等待时间request.timeout.ms 默认是30s
this.client = new ConsumerNetworkClient(
logContext,
netClient,
metadata,
time,
retryBackoffMs,
config.getInt(ConsumerConfig.REQUEST_TIMEOUT_MS_CONFIG),
heartbeatIntervalMs); //Will avoid blocking an extended period of time to prevent heartbeat thread starvation
// 获取消费者分区分配策略
this.assignors = ConsumerPartitionAssignor.getAssignorInstances(
config.getList(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG),
config.originals(Collections.singletonMap(ConsumerConfig.CLIENT_ID_CONFIG, clientId))
);
// no coordinator will be constructed for the default (null) group id
// 创建消费者协调器
// auto.commit.interval.ms 自动提交offset时间 默认5s
this.coordinator = !groupId.isPresent() ? null :
new ConsumerCoordinator(groupRebalanceConfig,
logContext,
this.client,
assignors,
this.metadata,
this.subscriptions,
metrics,
metricGrpPrefix,
this.time,
enableAutoCommit,
config.getInt(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG),
this.interceptors,
config.getBoolean(ConsumerConfig.THROW_ON_FETCH_STABLE_OFFSET_UNSUPPORTED));
// 配置抓数据的参数
// fetch.min.bytes 默认最少一次抓取1个字节
// fetch.max.bytes 默认最多一次抓取50m
// fetch.max.wait.ms 抓取等待最大时间 500ms
// max.partition.fetch.bytes 默认是1m
// max.poll.records 默认一次处理500条
// key 和 value 的反序列化
this.fetcher = new Fetcher<>(
logContext,
this.client,
config.getInt(ConsumerConfig.FETCH_MIN_BYTES_CONFIG),
config.getInt(ConsumerConfig.FETCH_MAX_BYTES_CONFIG),
config.getInt(ConsumerConfig.FETCH_MAX_WAIT_MS_CONFIG),
config.getInt(ConsumerConfig.MAX_PARTITION_FETCH_BYTES_CONFIG),
config.getInt(ConsumerConfig.MAX_POLL_RECORDS_CONFIG),
config.getBoolean(ConsumerConfig.CHECK_CRCS_CONFIG),
config.getString(ConsumerConfig.CLIENT_RACK_CONFIG),
this.keyDeserializer,
this.valueDeserializer,
this.metadata,
this.subscriptions,
metrics,
metricsRegistry,
this.time,
this.retryBackoffMs,
this.requestTimeoutMs,
isolationLevel,
apiVersions);
this.kafkaConsumerMetrics = new KafkaConsumerMetrics(metrics, metricGrpPrefix);
config.logUnused();
AppInfoParser.registerAppInfo(JMX_PREFIX, clientId, metrics, time.milliseconds());
log.debug("Kafka consumer initialized");
} catch (Throwable t) {
// call close methods if internal objects are already constructed; this is to prevent resource leak. see KAFKA-2121
// we do not need to call `close` at all when `log` is null, which means no internal objects were initialized.
if (this.log != null) {
close(0, true);
}
// now propagate the exception
throw new KafkaException("Failed to construct kafka consumer", t);
}
}
消费者订阅主题
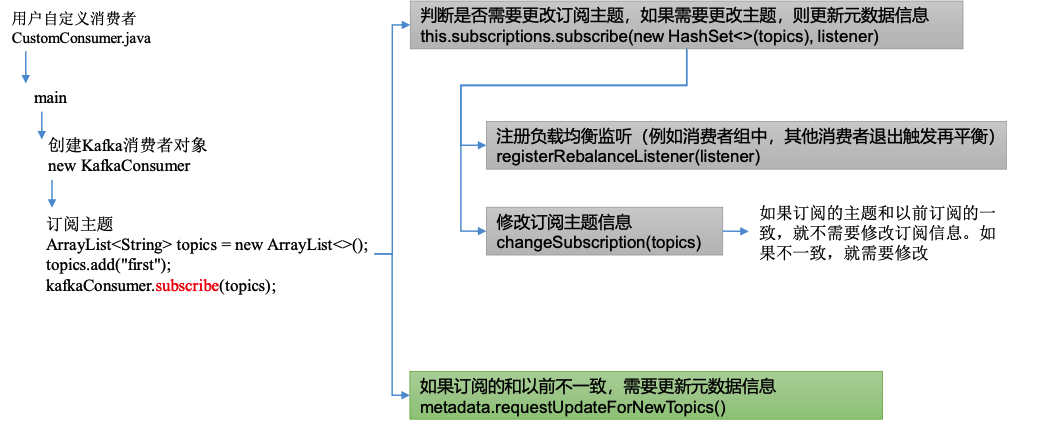
1)KafkaConsumer.subscribe(Collection<String> topics, ConsumerRebalanceListener listener)
public void subscribe(Collection<String> topics, ConsumerRebalanceListener listener) {
acquireAndEnsureOpen();
try {
maybeThrowInvalidGroupIdException();
// 要订阅的主题如果为null ,直接抛异常
if (topics == null)
throw new IllegalArgumentException("Topic collection to subscribe to cannot be null");
// 要订阅的主题如果为空
if (topics.isEmpty()) {
// treat subscribing to empty topic list as the same as unsubscribing
this.unsubscribe();
} else {
// 正常的处理操作
for (String topic : topics) {
// 如果为空 抛异常
if (Utils.isBlank(topic))
throw new IllegalArgumentException("Topic collection to subscribe to cannot contain null or empty topic");
}
throwIfNoAssignorsConfigured();
// 清空订阅异常主题的缓存数据
fetcher.clearBufferedDataForUnassignedTopics(topics);
log.info("Subscribed to topic(s): {}", Utils.join(topics, ", "));
// 判断是否需要更改订阅主题,如果需要更改主题,则更新元数据信息(主题了一个监听器listener) --> 2⃣️
if (this.subscriptions.subscribe(new HashSet<>(topics), listener))
// 更新订阅信息 --> 3⃣️
metadata.requestUpdateForNewTopics();
}
} finally {
release();
}
}
2)SubscriptionState.subscribe(Set<String> topics, ConsumerRebalanceListener listener)
public synchronized boolean subscribe(Set<String> topics, ConsumerRebalanceListener listener) {
// 注册负载均衡监听器
registerRebalanceListener(listener);
// 按照主题自动订阅模式
setSubscriptionType(SubscriptionType.AUTO_TOPICS);
// 判断是否需要更改订阅的主题
return changeSubscription(topics);
}
---------------------------------------------------------
private boolean changeSubscription(Set<String> topicsToSubscribe) {
// 如果传入的topics 和以前订阅的主题一致,那就不需要更改对应订阅的主题
if (subscription.equals(topicsToSubscribe))
return false;
subscription = topicsToSubscribe;
return true;
}
3)如果订阅的和以前不一致,需要更新元数据信息
public synchronized int requestUpdateForNewTopics() {
// Override the timestamp of last refresh to let immediate update.
this.lastRefreshMs = 0;
this.needPartialUpdate = true;
this.requestVersion++;
return this.updateVersion;
}
消费者拉取和处理数据
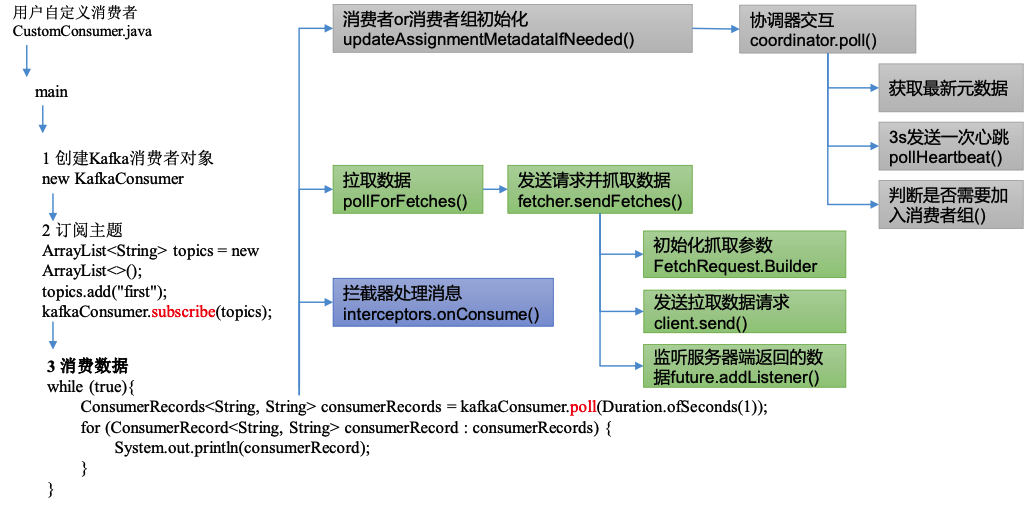
1)KafkaConsumer.poll()
public ConsumerRecords<K, V> poll(final Duration timeout) {
return poll(time.timer(timeout), true);
}
private ConsumerRecords<K, V> poll(final Timer timer, final boolean includeMetadataInTimeout) {
acquireAndEnsureOpen();
try {
// 记录开始拉取消息时间
this.kafkaConsumerMetrics.recordPollStart(timer.currentTimeMs());
if (this.subscriptions.hasNoSubscriptionOrUserAssignment()) {
throw new IllegalStateException("Consumer is not subscribed to any topics or assigned any partitions");
}
do {
client.maybeTriggerWakeup();
if (includeMetadataInTimeout) {
// 消费者或者消费者组的初始化 --> 2⃣️
// try to update assignment metadata BUT do not need to block on the timer for join group
updateAssignmentMetadataIfNeeded(timer, false);
} else {
while (!updateAssignmentMetadataIfNeeded(time.timer(Long.MAX_VALUE), true)) {
log.warn("Still waiting for metadata");
}
}
// 抓取数据 --> 3⃣️
final Map<TopicPartition, List<ConsumerRecord<K, V>>> records = pollForFetches(timer);
if (!records.isEmpty()) {
// before returning the fetched records, we can send off the next round of fetches
// and avoid block waiting for their responses to enable pipelining while the user
// is handling the fetched records.
//
// NOTE: since the consumed position has already been updated, we must not allow
// wakeups or any other errors to be triggered prior to returning the fetched records.
if (fetcher.sendFetches() > 0 || client.hasPendingRequests()) {
client.transmitSends();
}
// 拦截器处理数据 --> 4⃣️
return this.interceptors.onConsume(new ConsumerRecords<>(records));
}
} while (timer.notExpired());
return ConsumerRecords.empty();
} finally {
release();
this.kafkaConsumerMetrics.recordPollEnd(timer.currentTimeMs());
}
}
2)消费者组初始化流程
boolean updateAssignmentMetadataIfNeeded(final Timer timer, final boolean waitForJoinGroup) {
if (coordinator != null && !coordinator.poll(timer, waitForJoinGroup)) {
return false;
}
return updateFetchPositions(timer);
}
---------------------------------------------------------
public boolean poll(Timer timer, boolean waitForJoinGroup) {
// 获取最新元数据
maybeUpdateSubscriptionMetadata();
invokeCompletedOffsetCommitCallbacks();
if (subscriptions.hasAutoAssignedPartitions()) {
// 如果没有指定分区分配策略 直接抛异常
if (protocol == null) {
throw new IllegalStateException("User configured " + ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG +
" to empty while trying to subscribe for group protocol to auto assign partitions");
}
// Always update the heartbeat last poll time so that the heartbeat thread does not leave the
// group proactively due to application inactivity even if (say) the coordinator cannot be found.
// 3s心跳
pollHeartbeat(timer.currentTimeMs());
// ⭐️保证和Coordinator正常通信(寻找服务器端的coordinator)
if (coordinatorUnknown() && !ensureCoordinatorReady(timer)) {
return false;
}
// 判断是否需要加入消费者组
if (rejoinNeededOrPending()) {
if (subscriptions.hasPatternSubscription()) {
if (this.metadata.timeToAllowUpdate(timer.currentTimeMs()) == 0) {
this.metadata.requestUpdate();
}
if (!client.ensureFreshMetadata(timer)) {
return false;
}
maybeUpdateSubscriptionMetadata();
}
if (!ensureActiveGroup(waitForJoinGroup ? timer : time.timer(0L))) {
timer.update(time.milliseconds());
return false;
}
}
} else {
if (metadata.updateRequested() && !client.hasReadyNodes(timer.currentTimeMs())) {
client.awaitMetadataUpdate(timer);
}
}
// 是否自动提交offset
maybeAutoCommitOffsetsAsync(timer.currentTimeMs());
return true;
}
---------------------------------------------------------
protected synchronized boolean ensureCoordinatorReady(final Timer timer) {
// 如果找到coordinator,直接返回
if (!coordinatorUnknown())
return true;
// 如果没有找到,循环给服务器端发送请求,直到找到coordinator
do {
if (fatalFindCoordinatorException != null) {
final RuntimeException fatalException = fatalFindCoordinatorException;
fatalFindCoordinatorException = null;
throw fatalException;
}
// ⭐️创建一个查找Coordinator 的请求 并发送
final RequestFuture<Void> future = lookupCoordinator();
// 获取服务器返回的结果
client.poll(future, timer);
if (!future.isDone()) {
// ran out of time
break;
}
RuntimeException fatalException = null;
if (future.failed()) {
if (future.isRetriable()) {
log.debug("Coordinator discovery failed, refreshing metadata", future.exception());
client.awaitMetadataUpdate(timer);
} else {
fatalException = future.exception();
log.info("FindCoordinator request hit fatal exception", fatalException);
}
} else if (coordinator != null && client.isUnavailable(coordinator)) {
// we found the coordinator, but the connection has failed, so mark
// it dead and backoff before retrying discovery
markCoordinatorUnknown("coordinator unavailable");
timer.sleep(rebalanceConfig.retryBackoffMs);
}
clearFindCoordinatorFuture();
if (fatalException != null)
throw fatalException;
} while (coordinatorUnknown() && timer.notExpired());
return !coordinatorUnknown();
}
---------------------------------------------------------
protected synchronized RequestFuture<Void> lookupCoordinator() {
if (findCoordinatorFuture == null) {
// find a node to ask about the coordinator
Node node = this.client.leastLoadedNode();
if (node == null) {
log.debug("No broker available to send FindCoordinator request");
return RequestFuture.noBrokersAvailable();
} else {
// ⭐️有节点接收查找Coordinator请求
findCoordinatorFuture = sendFindCoordinatorRequest(node);
}
}
return findCoordinatorFuture;
}
---------------------------------------------------------
private RequestFuture<Void> sendFindCoordinatorRequest(Node node) {
// initiate the group metadata request
log.debug("Sending FindCoordinator request to broker {}", node);
// 创建发送Coordinator 请求数据信息
FindCoordinatorRequestData data = new FindCoordinatorRequestData()
.setKeyType(CoordinatorType.GROUP.id())
.setKey(this.rebalanceConfig.groupId);
// 进一步封装
FindCoordinatorRequest.Builder requestBuilder = new FindCoordinatorRequest.Builder(data);
return client.send(node, requestBuilder)
.compose(new FindCoordinatorResponseHandler());
}
3)拉取数据
private Map<TopicPartition, List<ConsumerRecord<K, V>>> pollForFetches(Timer timer) {
long pollTimeout = coordinator == null ? timer.remainingMs() :
Math.min(coordinator.timeToNextPoll(timer.currentTimeMs()), timer.remainingMs());
// if data is available already, return it immediately
// 第一次拉取不到数据
final Map<TopicPartition, List<ConsumerRecord<K, V>>> records = fetcher.fetchedRecords();
if (!records.isEmpty()) {
return records;
}
// send any new fetches (won't resend pending fetches)
// ⭐️发送请求并抓取数据
fetcher.sendFetches();
// We do not want to be stuck blocking in poll if we are missing some positions
// since the offset lookup may be backing off after a failure
// NOTE: the use of cachedSubscriptionHashAllFetchPositions means we MUST call
// updateAssignmentMetadataIfNeeded before this method.
if (!cachedSubscriptionHashAllFetchPositions && pollTimeout > retryBackoffMs) {
pollTimeout = retryBackoffMs;
}
log.trace("Polling for fetches with timeout {}", pollTimeout);
Timer pollTimer = time.timer(pollTimeout);
client.poll(pollTimer, () -> {
// since a fetch might be completed by the background thread, we need this poll condition
// to ensure that we do not block unnecessarily in poll()
return !fetcher.hasAvailableFetches();
});
timer.update(pollTimer.currentTimeMs());
// ⭐️把数据按照分区封装好后,一次处理默认 500 条数据
return fetcher.fetchedRecords();
}
---------------------------------------------------------
// 发送请求并抓取数据
public synchronized int sendFetches() {
// Update metrics in case there was an assignment change
sensors.maybeUpdateAssignment(subscriptions);
Map<Node, FetchSessionHandler.FetchRequestData> fetchRequestMap = prepareFetchRequests();
for (Map.Entry<Node, FetchSessionHandler.FetchRequestData> entry : fetchRequestMap.entrySet()) {
final Node fetchTarget = entry.getKey();
final FetchSessionHandler.FetchRequestData data = entry.getValue();
// maxWaitMs 默认是500ms
// minBytes 最少一次抓取1个字节
// maxBytes 最多一次抓取多少数据 默认50m
final FetchRequest.Builder request = FetchRequest.Builder
.forConsumer(this.maxWaitMs, this.minBytes, data.toSend())
.isolationLevel(isolationLevel)
.setMaxBytes(this.maxBytes)
.metadata(data.metadata())
.toForget(data.toForget())
.rackId(clientRackId);
if (log.isDebugEnabled()) {
log.debug("Sending {} {} to broker {}", isolationLevel, data.toString(), fetchTarget);
}
// 发送拉取数据请求
RequestFuture<ClientResponse> future = client.send(fetchTarget, request);
this.nodesWithPendingFetchRequests.add(entry.getKey().id());
// 监听服务器端返回的数据
future.addListener(new RequestFutureListener<ClientResponse>() {
@Override
public void onSuccess(ClientResponse resp) {
// 成功接收服务器端数据
synchronized (Fetcher.this) {
try {
// 获取服务器端响应数据
FetchResponse response = (FetchResponse) resp.responseBody();
FetchSessionHandler handler = sessionHandler(fetchTarget.id());
if (handler == null) {
log.error("Unable to find FetchSessionHandler for node {}. Ignoring fetch response.",
fetchTarget.id());
return;
}
if (!handler.handleResponse(response)) {
return;
}
Set<TopicPartition> partitions = new HashSet<>(response.responseData().keySet());
FetchResponseMetricAggregator metricAggregator = new FetchResponseMetricAggregator(sensors, partitions);
for (Map.Entry<TopicPartition, FetchResponseData.PartitionData> entry : response.responseData().entrySet()) {
TopicPartition partition = entry.getKey();
FetchRequest.PartitionData requestData = data.sessionPartitions().get(partition);
if (requestData == null) {
String message;
if (data.metadata().isFull()) {
message = MessageFormatter.arrayFormat(
"Response for missing full request partition: partition={}; metadata={}",
new Object[]{partition, data.metadata()}).getMessage();
} else {
message = MessageFormatter.arrayFormat(
"Response for missing session request partition: partition={}; metadata={}; toSend={}; toForget={}",
new Object[]{partition, data.metadata(), data.toSend(), data.toForget()}).getMessage();
}
// Received fetch response for missing session partition
throw new IllegalStateException(message);
} else {
long fetchOffset = requestData.fetchOffset;
FetchResponseData.PartitionData partitionData = entry.getValue();
log.debug("Fetch {} at offset {} for partition {} returned fetch data {}",
isolationLevel, fetchOffset, partition, partitionData);
Iterator<? extends RecordBatch> batches = FetchResponse.recordsOrFail(partitionData).batches().iterator();
short responseVersion = resp.requestHeader().apiVersion();
// 把数据按照分区,添加到消息队列里面
completedFetches.add(new CompletedFetch(partition, partitionData,
metricAggregator, batches, fetchOffset, responseVersion));
}
}
sensors.fetchLatency.record(resp.requestLatencyMs());
} finally {
nodesWithPendingFetchRequests.remove(fetchTarget.id());
}
}
}
@Override
public void onFailure(RuntimeException e) {
synchronized (Fetcher.this) {
try {
FetchSessionHandler handler = sessionHandler(fetchTarget.id());
if (handler != null) {
handler.handleError(e);
}
} finally {
nodesWithPendingFetchRequests.remove(fetchTarget.id());
}
}
}
});
}
return fetchRequestMap.size();
}
---------------------------------------------------------
// 把数据按照分区封装好后,一次处理最大条数默认 500 条数据
public Map<TopicPartition, List<ConsumerRecord<K, V>>> fetchedRecords() {
Map<TopicPartition, List<ConsumerRecord<K, V>>> fetched = new HashMap<>();
Queue<CompletedFetch> pausedCompletedFetches = new ArrayDeque<>();
// 每次处理的最多条数是500条
int recordsRemaining = maxPollRecords;
try {
while (recordsRemaining > 0) {
if (nextInLineFetch == null || nextInLineFetch.isConsumed) {
// 从缓存中获取数据
CompletedFetch records = completedFetches.peek();
// 如果没有数据了 可以退出循环
if (records == null) break;
if (records.notInitialized()) {
try {
nextInLineFetch = initializeCompletedFetch(records);
} catch (Exception e) {
FetchResponseData.PartitionData partition = records.partitionData;
if (fetched.isEmpty() && FetchResponse.recordsOrFail(partition).sizeInBytes() == 0) {
completedFetches.poll();
}
throw e;
}
} else {
nextInLineFetch = records;
}
// 从缓存中拉取数据
completedFetches.poll();
} else if (subscriptions.isPaused(nextInLineFetch.partition)) {
log.debug("Skipping fetching records for assigned partition {} because it is paused", nextInLineFetch.partition);
pausedCompletedFetches.add(nextInLineFetch);
nextInLineFetch = null;
} else {
List<ConsumerRecord<K, V>> records = fetchRecords(nextInLineFetch, recordsRemaining);
if (!records.isEmpty()) {
TopicPartition partition = nextInLineFetch.partition;
List<ConsumerRecord<K, V>> currentRecords = fetched.get(partition);
if (currentRecords == null) {
fetched.put(partition, records);
} else {
List<ConsumerRecord<K, V>> newRecords = new ArrayList<>(records.size() + currentRecords.size());
newRecords.addAll(currentRecords);
newRecords.addAll(records);
fetched.put(partition, newRecords);
}
recordsRemaining -= records.size();
}
}
}
} catch (KafkaException e) {
if (fetched.isEmpty())
throw e;
} finally {
// add any polled completed fetches for paused partitions back to the completed fetches queue to be
// re-evaluated in the next poll
completedFetches.addAll(pausedCompletedFetches);
}
return fetched;
}
4)拦截器处理数据
public ConsumerRecords<K, V> onConsume(ConsumerRecords<K, V> records) {
ConsumerRecords<K, V> interceptRecords = records;
for (ConsumerInterceptor<K, V> interceptor : this.interceptors) {
try {
// 每个拦截器都会对数据进行加工
interceptRecords = interceptor.onConsume(interceptRecords);
} catch (Exception e) {
// do not propagate interceptor exception, log and continue calling other interceptors
log.warn("Error executing interceptor onConsume callback", e);
}
}
return interceptRecords;
}
消费者 Offset 提交
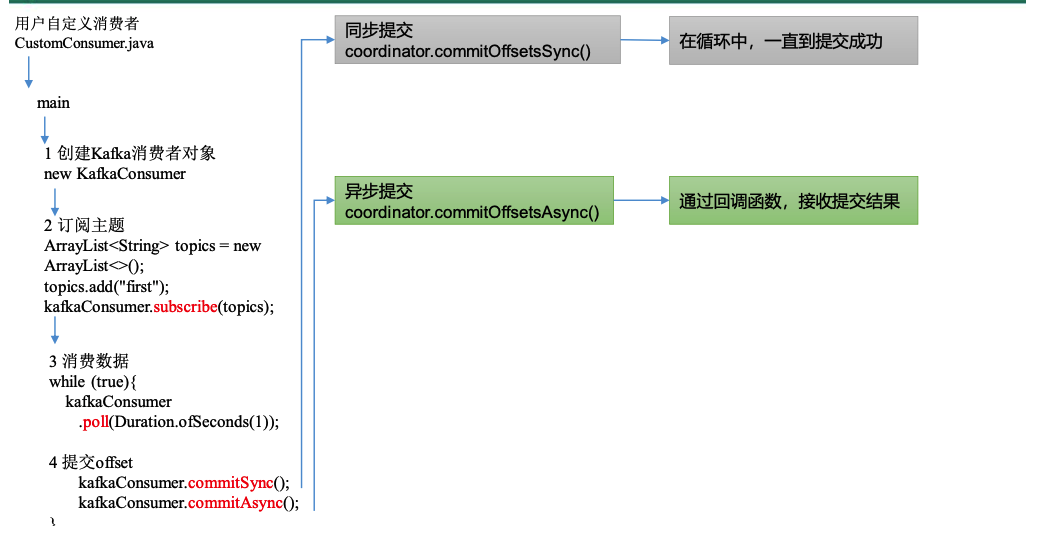
手动同步提交
1)commitSync()
public void commitSync(final Map<TopicPartition, OffsetAndMetadata> offsets, final Duration timeout) {
acquireAndEnsureOpen();
try {
maybeThrowInvalidGroupIdException();
offsets.forEach(this::updateLastSeenEpochIfNewer);
// 同步提交 --> 2⃣️
if (!coordinator.commitOffsetsSync(new HashMap<>(offsets), time.timer(timeout))) {
throw new TimeoutException("Timeout of " + timeout.toMillis() + "ms expired before successfully " +
"committing offsets " + offsets);
}
} finally {
release();
}
}
2)commitOffsetsSync()
public boolean commitOffsetsSync(Map<TopicPartition, OffsetAndMetadata> offsets, Timer timer) {
invokeCompletedOffsetCommitCallbacks();
if (offsets.isEmpty())
return true;
do {
if (coordinatorUnknown() && !ensureCoordinatorReady(timer)) {
return false;
}
// 发送提交请求
RequestFuture<Void> future = sendOffsetCommitRequest(offsets);
client.poll(future, timer);
// We may have had in-flight offset commits when the synchronous commit began. If so, ensure that
// the corresponding callbacks are invoked prior to returning in order to preserve the order that
// the offset commits were applied.
invokeCompletedOffsetCommitCallbacks();
// 提交成功
if (future.succeeded()) {
if (interceptors != null)
interceptors.onCommit(offsets);
return true;
}
if (future.failed() && !future.isRetriable())
throw future.exception();
timer.sleep(rebalanceConfig.retryBackoffMs);
} while (timer.notExpired());
return false;
}
手动异步提交
1)commitAsync()
public void commitAsync(final Map<TopicPartition, OffsetAndMetadata> offsets, OffsetCommitCallback callback) {
acquireAndEnsureOpen();
try {
maybeThrowInvalidGroupIdException();
log.debug("Committing offsets: {}", offsets);
offsets.forEach(this::updateLastSeenEpochIfNewer);
// 提交offset --> 2⃣️
coordinator.commitOffsetsAsync(new HashMap<>(offsets), callback);
} finally {
release();
}
}
2)commitOffsetsAsync()
public void commitOffsetsAsync(final Map<TopicPartition, OffsetAndMetadata> offsets, final OffsetCommitCallback callback) {
invokeCompletedOffsetCommitCallbacks();
if (!coordinatorUnknown()) {
doCommitOffsetsAsync(offsets, callback);
} else {
// we don't know the current coordinator, so try to find it and then send the commit
// or fail (we don't want recursive retries which can cause offset commits to arrive
// out of order). Note that there may be multiple offset commits chained to the same
// coordinator lookup request. This is fine because the listeners will be invoked in
// the same order that they were added. Note also that AbstractCoordinator prevents
// multiple concurrent coordinator lookup requests.
pendingAsyncCommits.incrementAndGet();
// 监听提交 offset 的结果
lookupCoordinator().addListener(new RequestFutureListener<Void>() {
@Override
public void onSuccess(Void value) {
pendingAsyncCommits.decrementAndGet();
doCommitOffsetsAsync(offsets, callback);
client.pollNoWakeup();
}
@Override
public void onFailure(RuntimeException e) {
pendingAsyncCommits.decrementAndGet();
completedOffsetCommits.add(new OffsetCommitCompletion(callback, offsets,
new RetriableCommitFailedException(e)));
}
});
}
// ensure the commit has a chance to be transmitted (without blocking on its completion).
// Note that commits are treated as heartbeats by the coordinator, so there is no need to
// explicitly allow heartbeats through delayed task execution.
client.pollNoWakeup();
}
服务器源码
1)程序的入口 Kafka.scala
def main(args: Array[String]): Unit = {
try {
// 获取相关参数
val serverProps = getPropsFromArgs(args)
// 创建服务
val server = buildServer(serverProps)
try {
if (!OperatingSystem.IS_WINDOWS && !Java.isIbmJdk)
new LoggingSignalHandler().register()
} catch {
case e: ReflectiveOperationException =>
warn("Failed to register optional signal handler that logs a message when the process is terminated " +
s"by a signal. Reason for registration failure is: $e", e)
}
// attach shutdown handler to catch terminating signals as well as normal termination
Exit.addShutdownHook("kafka-shutdown-hook", {
try server.shutdown()
catch {
case _: Throwable =>
fatal("Halting Kafka.")
// Calling exit() can lead to deadlock as exit() can be called multiple times. Force exit.
Exit.halt(1)
}
})
// 启动服务
try server.startup()
catch {
case _: Throwable =>
// KafkaServer.startup() calls shutdown() in case of exceptions, so we invoke `exit` to set the status code
fatal("Exiting Kafka.")
Exit.exit(1)
}
server.awaitShutdown()
}
catch {
case e: Throwable =>
fatal("Exiting Kafka due to fatal exception", e)
Exit.exit(1)
}
Exit.exit(0)
}
既已览卷至此,何不品评一二: