Kafka学习笔记 快速入门
Kafka概述
Kafka是一个分布式的基于发布/订阅模式的消息队列(Message Queue),主要应用于大数据实时处理领域。
消息队列的两种模式
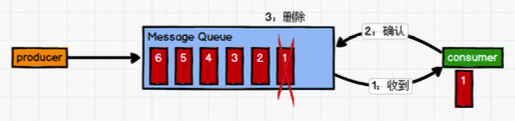
点对点模式
一对一,消费者主动拉取数据,消息收到后消息清除。消息生产者生产消息发送到 Queue 中,然后消息消费者从 Queue 中取出并且消费消息。消息被消费以后,Queue 中不再有存储,所以消息消费者不可能消费到已经被消费的消息。 Queue 支持存在多个消费者,但是对一个消息而言,只会有一个消费者可以消费。
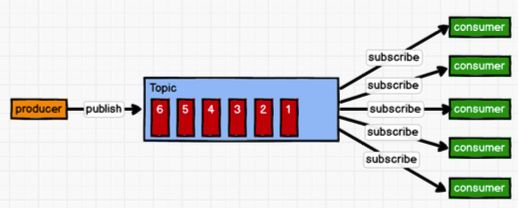
发布/订阅模式
一对多,消费者消费数据之后不会清除消息。消息生产者(发布)将消息发布到 topic 中,同时有多个消息消费者(订阅)消费该消息。和点对点方式不同,发布到 topic 的消息会被所有订阅者消费。该模式具体可分为拉和推两种方式:
- 队列主动推送:各个消费者处理的速率不同,可能会导致消费者资源浪费或不足。
- 消费者主动拉取:长轮询
Kafka 基础架构
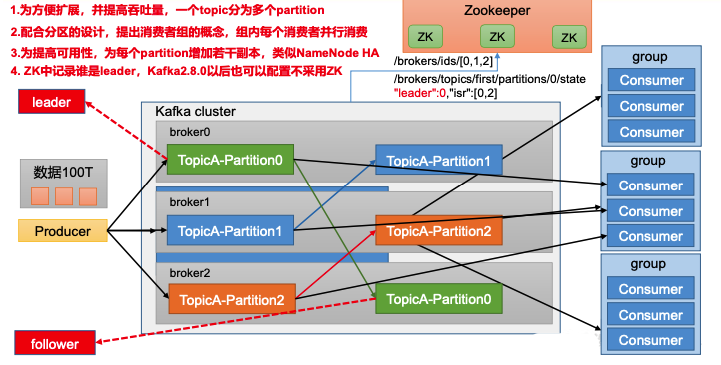
- Producer:消息生产者,就是向 Kafka broker 发消息的客户端
- Consumer:消息消费者,向 Kafka broker 取消息的客户端
- Consumer Group(CG):消费者组,由多个consumer组成。消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费;消费者组之间互不 影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
- Broker:一台 Kafka 服务器就是一个 broker。一个集群由多个 broker 组成。一个 broker 可以容纳多个 topic。
- Topic:可以理解为一个队列,生产者和消费者面向的都是一个 topic。
- Partition:为了实现扩展性,一个非常大的 topic 可以分布到多个 broker(即服 务器)上,一个 topic 可以分为多个 partition,每个 partition 是一个有序的队列。
- Replica:副本。一个 topic 的每个分区都有若干个副本,一个 Leader 和若干个 Follower。
- Leader:每个分区多个副本的“主”,生产者发送数据的对象,以及消费者消费数 据的对象都是 Leader。
- Follower:每个分区多个副本中的“从”,实时从 Leader 中同步数据,保持和 Leader 数据的同步。Leader 发生故障时,某个 Follower 会成为新的 Leader。
Kafka快速入门
单机部署
1)解压安装包
tar -zxvf kafka_2.12-3.0.0.tgz -C /opt/module/
2)创建logs日志文件夹
mkdir ~/Application/kafka_2.12-3.0.0/logs
3)修改配置文件
vim kafka_2.12-3.0.0/config/server.properties
#broker 的全局唯一编号,不能重复 broker.id=0
#删除 topic 功能使能
delete.topic.enable=true
#处理网络请求的线程数量
num.network.threads=3
#用来处理磁盘 IO 的现成数量
num.io.threads=8
#发送套接字的缓冲区大小
socket.send.buffer.bytes=102400
#接收套接字的缓冲区大小
socket.receive.buffer.bytes=102400
#请求套接字的缓冲区大小
socket.request.max.bytes=104857600
#kafka 运行数据和日志存放的路径
log.dirs=~/Application/kafka_2.12-3.0.0/logs
#topic 在当前 broker 上的分区个数
num.partitions=1
#用来恢复和清理 data 下数据的线程数量
num.recovery.threads.per.data.dir=1
#segment 文件保留的最长时间,超时将被删除
log.retention.hours=168
#配置连接 Zookeeper 集群地址
zookeeper.connect=localhost:2181/kafka
4)依次启动zookeeper和kafka(Kafka会按照默认,在9092端口上运行,并连接zookeeper的默认端口:2182)
cd ~/Applications/ZooKeeper
bin/zkServer.sh start
~/Application/kafka_2.12-3.0.0
sh bin/kafka-server-start.sh -daemon config/server.properties # -daemon 后台启动kafka
如kafka启动报错:在 server.properties 找到 log.dirs 配置的路径。将该路径下的所有文件删除,或者编辑meta.properties文件修改里面的cluster.id即可。
ERROR Fatal error during KafkaServer startup. Prepare to shutdown (kafka.server.KafkaServer)
kafka.common.InconsistentClusterIdException: The Cluster ID kVSgfurUQFGGpHMTBqBPiw doesn't match stored clusterId Some(0Qftv9yBTAmf2iDPSlIk7g) in meta.properties. The broker is trying to join the wrong cluster. Configured zookeeper.connect may be wrong.
at kafka.server.KafkaServer.startup(KafkaServer.scala:220)
at kafka.server.KafkaServerStartable.startup(KafkaServerStartable.scala:44)
at kafka.Kafka$.main(Kafka.scala:84)
at kafka.Kafka.main(Kafka.scala)
主题命令行操作
1)查看操作主题命令参数
bin/kafka-topics.sh
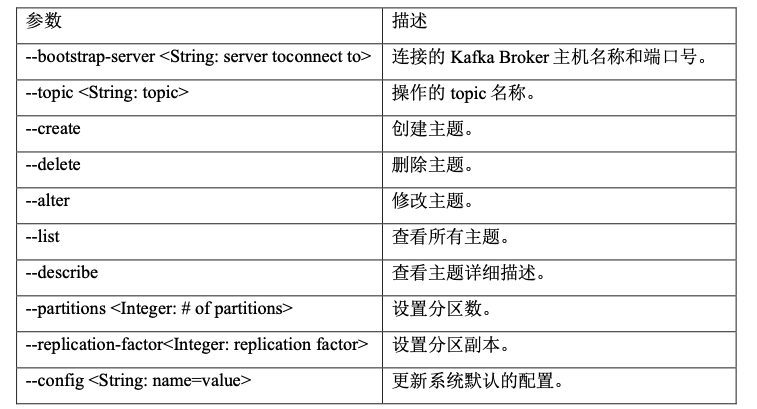
2)查看当前服务器中的所有 topic
bin/kafka-topics.sh --bootstrap-server localhost:9092 --list
3)创建 first topic
# --topic 定义topic名 --replication-factor 定义副本数 --partitions 定义分区数
bin/kafka-topics.sh --bootstrap-server localhost:9092 --create --partitions 1 --replication-factor 3 --topic first
4)查看 first 主题的详情
bin/kafka-topics.sh --bootstrap-server localhost:9092 --describe --topic first
5)修改分区数(注意:分区数只能增加,不能减少)
bin/kafka-topics.sh --bootstrap-server localhost:9092 --alter --topic first --partitions 3
6)删除 topic
bin/kafka-topics.sh --bootstrap-server localhost:9092 --delete --topic first
生产者命令行操作
1)查看操作生产者命令参数
bin/kafka-console-producer.sh

2)发送消息
bin/kafka-console-producer.sh --bootstrap-server localhost:9092 --topic first
>hello world
消费者命令行操作
1)查看操作消费者命令参数
| 参数 | 描述 |
|---|---|
| –bootstrap-server <String: server toconnect to> | 连接的 Kafka Broker 主机名称和端口号 |
| –topic <String: topic> | 操作的 topic 名称 |
| –from-beginning | 从头开始消费 |
| –group <String: consumer group id> | 指定消费者组名称 |
2)消费消息
# 消费 first 主题中的数据
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic first
# 把主题中所有的数据都读取出来(包括历史数据)
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --from-beginning --topic first
既已览卷至此,何不品评一二: