Nacos原理
服务注册与发现
服务注册
服务注册,这个是个动作,那么注册到哪里了呢,那就需要在注册中心有个容器来存储注册上来的服务。这个容器可能是map,数组,持久化的mysql,mongodb。有了容器存储之后那我们就想那注册上来的是啥呢?也就是存在容器中的内容是什么呢?其实放在容器中的主要信息就是微服务各个节点所在的ip+端口。之后调用端才能知道你服务提供方在哪提供服务,这样调用端才能顺着这条线去调用服务。
作为注册中心的功能来说,Nacos提供的功能与其他主流框架很类似,基本都是围绕服务实例注册、实例健康检查、服务实例获取这三个核心来实现的。
以Java版本的Nacos客户端为例,服务注册基本流程:
- 服务实例启动将自身注册到Nacos注册中心,随后维持与注册中心的心跳;
- 心跳维持策略为每5秒向Nacos Server发送一次心跳,并携带实例信息(服务名、实例IP、端口等);
- Nacos Server也会向Client主动发起健康检查,支持TCP/Http;
- 15秒内无心跳且健康检查失败则认为实例不健康,如果30秒内健康检查失败则移除实例;
- 服务消费者通过注册中心获取实例,并发起调用;
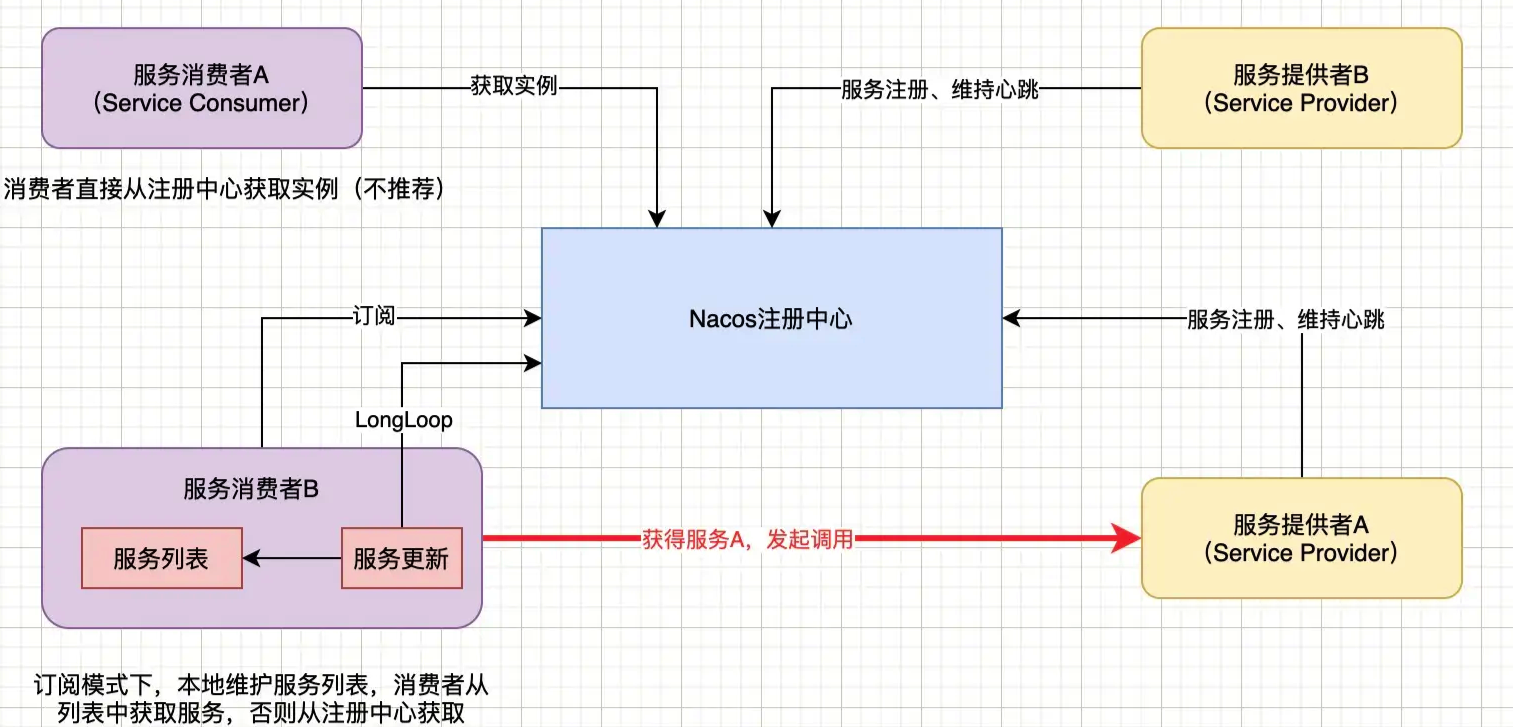
服务发现
服务发现支持两种场景:
- 服务消费者直接向注册中心发送获取某服务实例的请求,注册中心返回所有可用实例,但一般不推荐此种方式;
- ⭐️ 服务消费者向注册中心订阅某服务,并提交一个监听器,当注册中心中服务发生变化时,监听器会收到通知,消费者更新本地服务实例列表,以保证所有的服务均可用。
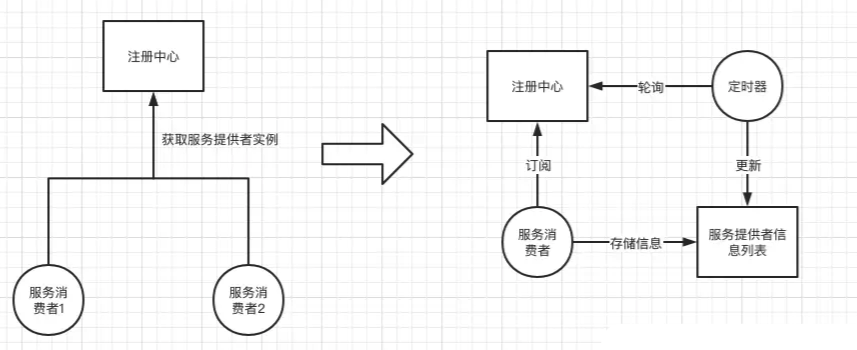
如上图如果消费者订阅了服务,那么会在本地基于内存维护一个服务信息列表,之后进行服务调用是直接从本地列表获取对应的服务实例进行调用,否则去主从中心获取服务实例。
二者之间是怎么调用的
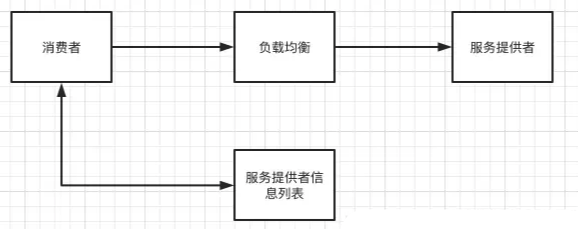
服务提供者与服务消费者之间是通过feign+ribbon进行配合调用的,feign提供http请求的封装以及调用,ribbon提供负载均衡。负载均衡有很多中实现方式,包括轮询法,随机方法法,对请求ip做hash后取模等等。 Nacos 的客户端在获取到服务的完整实例列表后,会在客户端进行负载均衡算法来获取一个可用的实例,默认使用的是随机获取的方式。
配置中心原理
客户端
获取配置
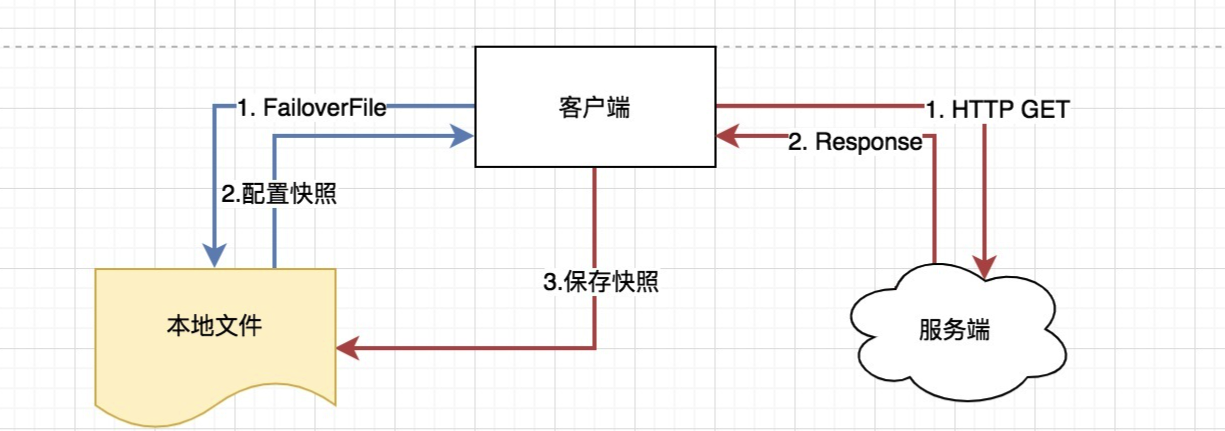
获取配置的主要方法是 NacosConfigService 类的 getConfigInner 方法,通常情况下该方法直接从本地文件中取得配置的值,如果本地文件不存在或者内容为空,则再通过 HTTP GET 方法从远端拉取配置,并保存到本地快照中。
当通过 HTTP 获取远端配置时,Nacos 提供了两种熔断策略,一是超时时间,二是最大重试次数,默认重试三次。
注册监听器
配置中心客户端对某个配置项注册监听器是很常见的需求,达到在配置项变更的时候执行回调的功能。
iconfig.addListener(dataId, group, ml);
iconfig.getConfigAndSignListener(dataId, group, 1000, ml);
Nacos 可以通过以上方式注册监听器,它们内部的实现均是调用 ClientWorker 类的 addCacheDataIfAbsent。其中 CacheData 是一个维护配置项和其下注册的所有监听器的实例。
所有的 CacheData 都保存在 ClientWorker 类中的原子 cacheMap 中,其内部的核心成员有:
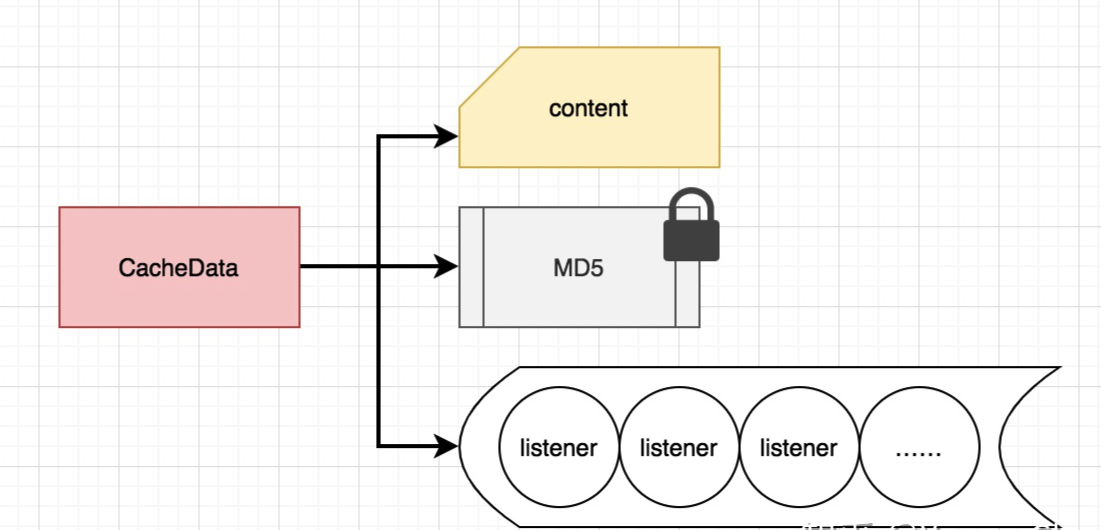
其中,content 是配置内容,MD5 值是用来检测配置是否发生变更的关键,内部还维护着一个若干监听器组成的数组,一旦发生变更则依次回调这些监听器。
配置长轮询
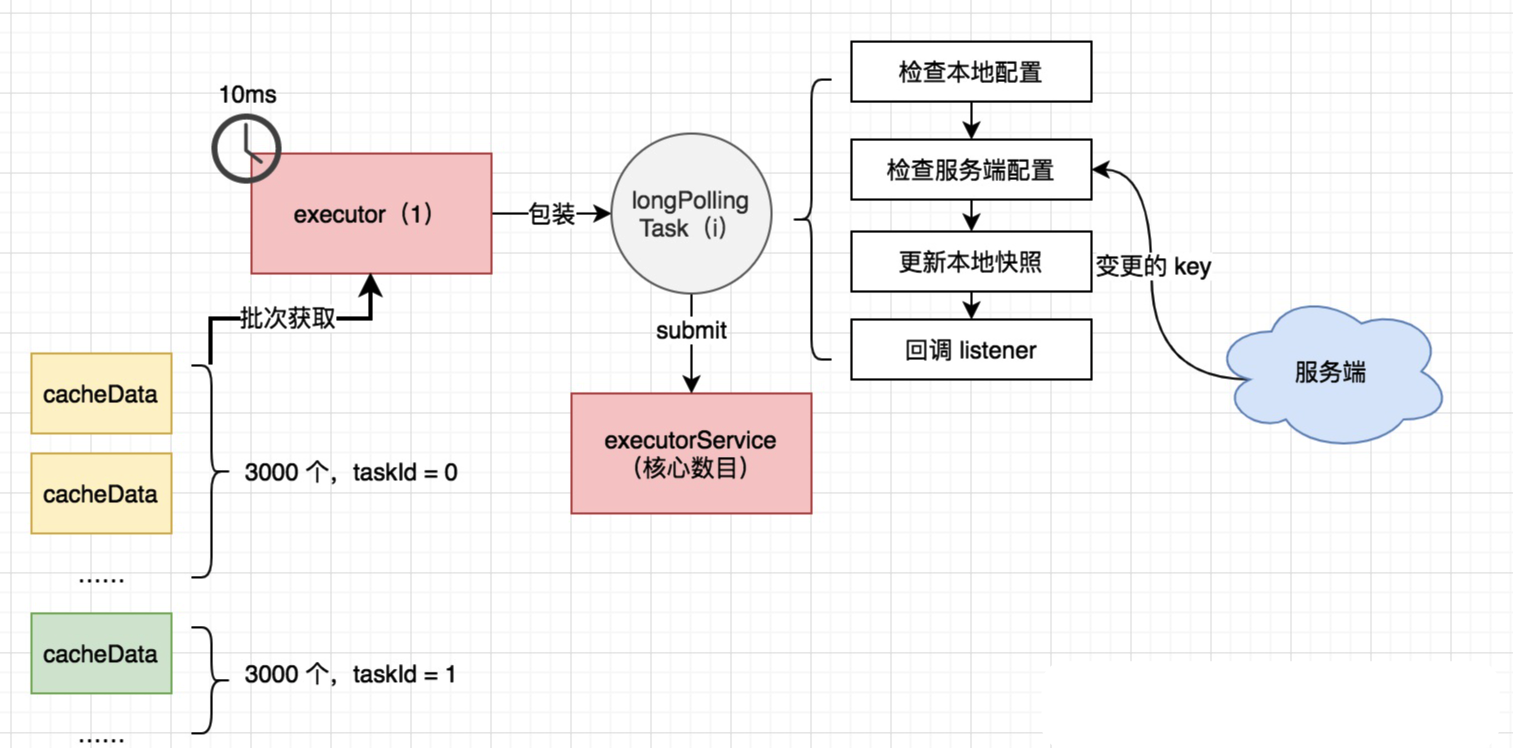
ClientWorker 通过其下的两个线程池完成配置长轮询的工作,一个是单线程的 executor,每隔 10ms 按照每 3000 个配置项为一批次捞取待轮询的 cacheData 实例,将其包装成为一个 LongPollingTask 提交进入第二个线程池 executorService 处理。
该长轮询任务内部主要分为四步:
- 检查本地配置,忽略本地快照不存在的配置项,检查是否存在需要回调监听器的配置项
- 如果本地没有配置项的,从服务端拿,返回配置内容发生变更的键值列表
- 每个键值再到服务端获取最新配置,更新本地快照,补全之前缺失的配置
- 检查
MD5标签是否一致,不一致需要回调监听器
如果该轮询任务抛出异常,等待一段时间再开始下一次调用,减轻服务端压力。另外,Nacos 在 HTTP 工具类中也有限流器的代码,通过多种手段降低轮询或者大流量情况下的风险。下文还会讲到,如果在服务端没有发现变更的键值,那么服务端会夯住这个 HTTP 请求一段时间(客户端侧默认传递的超时是 30s),以此进一步减轻客户端的轮询频率和服务端的压力。
服务端
配置 Dump
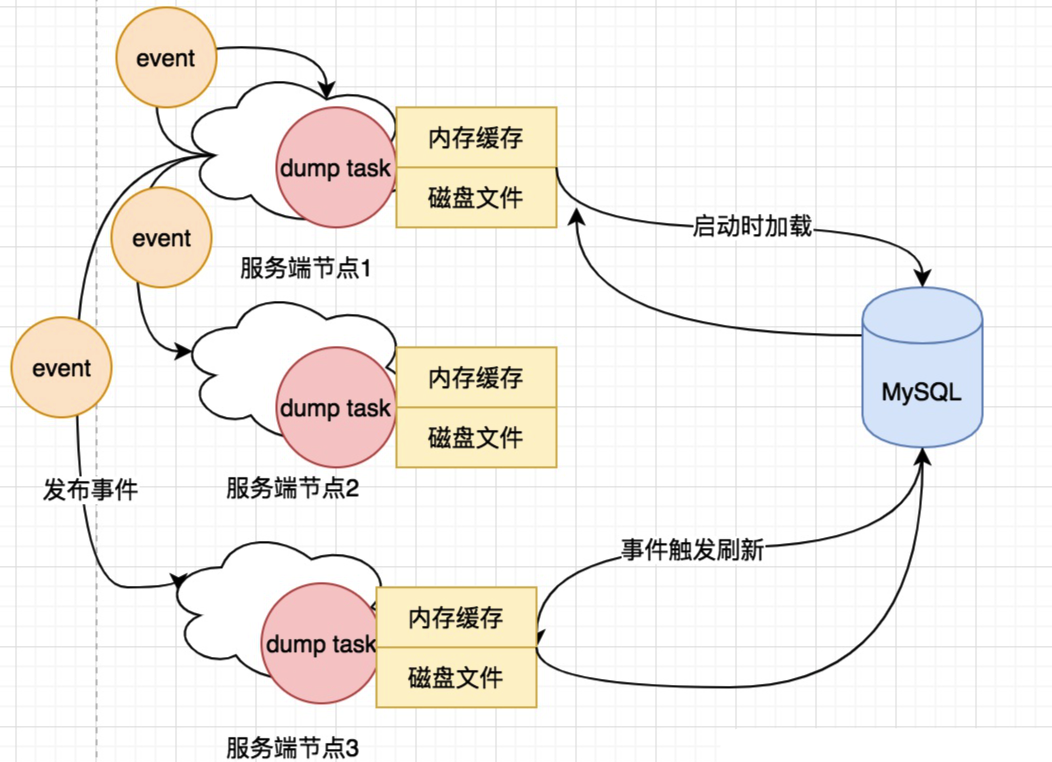
服务端启动时就会依赖 DumpService 的 init 方法,从数据库中 load 配置存储在本地磁盘上,并将一些重要的元信息例如 MD5 值缓存在内存中。服务端会根据心跳文件中保存的最后一次心跳时间,来判断到底是从数据库 dump 全量配置数据还是部分增量配置数据(如果机器上次心跳间隔是 6h 以内的话)。
全量 dump 当然先清空磁盘缓存,然后根据主键 ID 每次捞取一千条配置刷进磁盘和内存。增量 dump 就是捞取最近六小时的新增配置(包括更新的和删除的),先按照这批数据刷新一遍内存和文件,再根据内存里所有的数据全量去比对一遍数据库,如果有改变的再同步一次,相比于全量 dump 的话会减少一定的数据库 IO 和磁盘 IO 次数。
配置注册
Nacos 服务端是一个 SpringBoot 实现的服务,注册配置主要代码位于 ConfigController 和 ConfigServletInner 中。服务端一般是多节点部署的集群,因此请求一开始只会打到一台机器,这台机器将配置插入 MySQL 中进行持久化,这部分代码很简单不再赘述。
因为服务端并不是针对每次配置查询都去访问 MySQL 的,而是会依赖 dump 功能在本地文件中将配置缓存起来。因此当单台机器保存完毕配置之后,需要通知其他机器刷新内存和本地磁盘中的文件内容,因此它会发布一个名为 ConfigDataChangeEvent 的事件,这个事件会通过 HTTP 调用通知所有集群节点(包括自身),触发本地文件和内存的刷新。
处理长轮询
上文提到,客户端会有一个长轮询任务,拉取服务端的配置变更,那么服务端是如何处理这个长轮询任务的呢?源码逻辑位于 LongPollingService 类,其中有一个 Runnable 任务名为 ClientLongPolling,服务端会将受到的轮询请求包装成一个 ClientLongPolling 任务,该任务持有一个 AsyncContext 响应对象(Servlet 3.0 的新机制),通过定时线程池延后 29.5s 执行。
为什么比客户端 30s 的超时时间提前 500ms 返回是为了最大程度上保证客户端不会因为网络延时造成超时
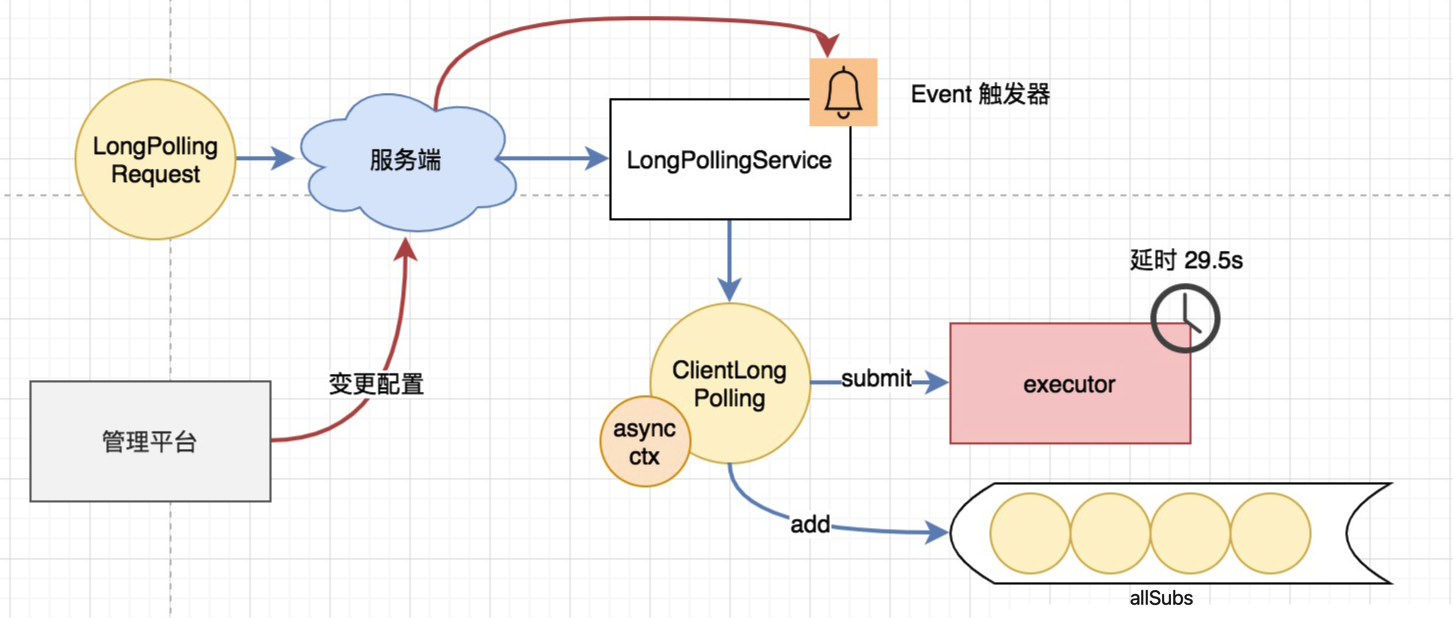
这里需要注意的是,在 ClientLongPolling 任务被提交进入线程池待执行的同时,服务端也通过一个队列 allSubs 保存了所有正在被夯住的轮询请求,这是因为在配置项被夯住的期间内,如果用户通过管理平台操作了配置项变更、或者服务端该节点收到了来自其他节点的 dump 刷新通知,那么都应立即取消夯住的任务,及时通知客户端数据发生了变更。
为了达到这个目的,LongPollingService 类继承自 Event 接口,实际上本身是个事件触发器,需要实现 onEvent 方法,其事件类型是 LocalDataChangeEvent。
当服务端在请求被夯住的期间接收到某项配置变更时,就会发布一个 LocalDataChangeEvent 类型的事件通知(注意同上文中的 ConfigDataChangeEvent 区别),之后会将这个变更包装成一个 DataChangeTask 异步执行,内容就是从 allSubs 中找出夯住的 ClientLongPolling 请求,写入变更强制其立即返回。
总结
nacos是采用了拉模式是一种特殊的拉模式,也就是我们通常听的长轮询机制:
1)如果服务端配置发生了变化
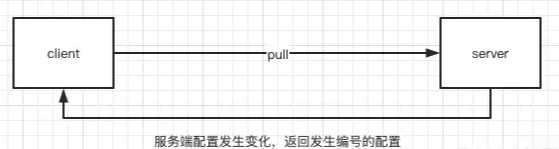
2)如果服务端配置与客户端一直没有变化
如果客户端拉取发现自己与服务端配置是一致的(其实是通过MD5判断的)那么服务端会先拿住这个请求不返回,直到这段时间内配置有变化了才把刚才拿住的请求返回。他的步骤是nacos服务端收到请求后检查配置是否发生变化,如果没有则开启定时任务,延迟29.5s执行。同时把当前客户端的连接请求放入队列。那么此时服务端并没有将结果返回给客户端,当有以下2种情况的时候才触发返回。
- 就是等待29.5s后触发自动检查
- 在29.5s内有配置进行了更改
经过这2种情况才完成这次的pull操作。这种的好处就是保证了客户端的配置能及时变化更新,也减少了轮询给服务端带来的压力。所以之前文章我们说过这个长链接会话超时时间默认是30s。
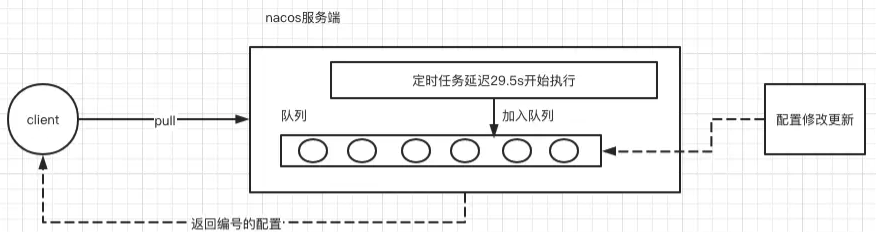
简单总结一下整个过程:
- 客户端发起长轮询请求
- 服务端收到请求以后,先比较服务端缓存中的数据是否相同,如果不同,则直接返回
- 如果相同,则通过schedule延迟29.5s之后再执行比较
- 为了保证当服务端在29.5s之内发生数据变化能够及时通知给客户端,服务端采用事件订阅的方式来监听服务端本地数据变化的事件,一旦收到事件,则触发DataChangeTask的通知,并且遍历allStubs队列中的ClientLongPolling,把结果写回到客户端,就完成了一次数据的推送
- 如果 DataChangeTask 任务完成了数据的 “推送” 之后,ClientLongPolling 中的调度任务又开始执行了怎么办呢?很简单,只要在进行 “推送” 操作之前,先将原来等待执行的调度任务取消掉就可以了,这样就防止了推送操作写完响应数据之后,调度任务又去写响应数据,这时肯定会报错的。所以,在ClientLongPolling方法中,最开始的一个步骤就是删除订阅事件
所以总的来说,Nacos采用推+拉的形式,来解决最开始关于长轮训时间间隔的问题。当然,30s这个时间是可以设置的,而之所以定30s,应该是一个经验值。
参考
既已览卷至此,何不品评一二: