synchronized 锁升级过程
用户态与内核态
JDK早期,synchronized 叫做重量级锁, 申请锁资源必须通过kernel, 系统调用(从用户态向内核态调用)
;hello.asm
;write(int fd, const void *buffer, size_t nbytes)
section data
msg db "Hello", 0xA
len equ $ - msg
section .text
global _start
_start:
mov edx, len
mov ecx, msg
mov ebx, 1 ;文件描述符1 std_out
mov eax, 4 ;write函数系统调用号 4
int 0x80
mov ebx, 0
mov eax, 1 ;exit函数系统调用号
int 0x80 ; 0x80H软中断 触发系统调用
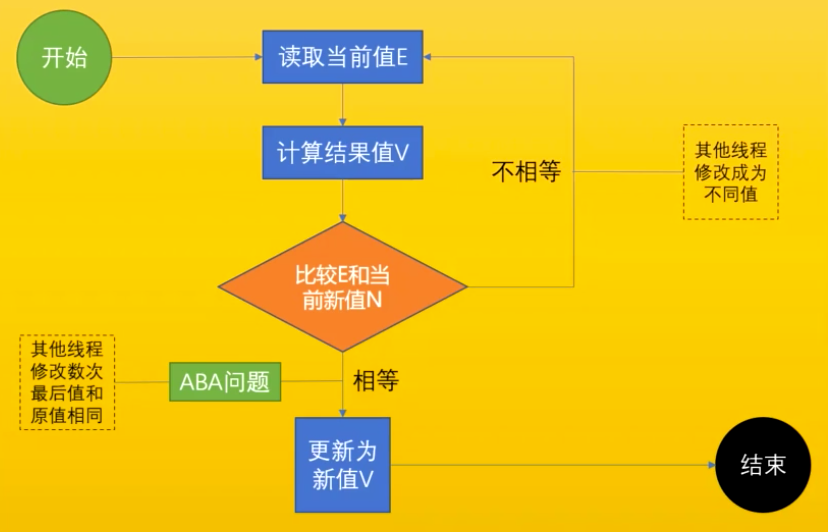
CAS
Compare And Swap (Compare And Exchange) / 自旋 / 自旋锁 / 无锁 (无重量锁)。
- 在大多数处理器的指令中,都会实现 CAS 相关的指令,这一条指令就可以完成“比较并交换”的操作,也正是由于这是一条(而不是多条)CPU 指令,所以 CAS 相关的指令是具备原子性的,这个组合操作在执行期间不会被打断,这样就能保证并发安全。由于这个原子性是由 CPU 保证的,所以无需我们程序员来操心。
- Java 中的CAS操作只是对CPU的 cmpxchgq 指令的一层封装。它的功能就是一次只原子地修改一个变量。
- 因为经常配合循环操作,直到完成为止,所以泛指一类操作。 cas(v, a, b) ,变量v,期待值a, 修改值b
- 是一种乐观锁
解决ABA问题
描述:比较的时候经过了多次修改最后值和原来的值相同。
解决办法(版本号 AtomicStampedReference),基础类型简单值不需要版本号。
CAS开销
CAS(比较并交换)是CPU指令级的操作,只有一步原子操作,所以非常快。而且CAS避免了请求操作系统来裁定锁的问题,不用麻烦操作系统,直接在CPU内部就搞定了。但CAS就没有开销了吗?不!有cache miss的情况。这个问题比较复杂,首先需要了解CPU的硬件体系结构:伪共享和缓存行
如果线程1在CPU核心1上读写变量X,同时线程2在CPU核心2上读写变量Y,不幸的是变量X和变量Y在同一个缓存行上,每一个线程为了对缓存行进行读写,都要竞争并获得缓存行的读写权限,如果线程2在CPU核心2上获得了对缓存行进行读写的权限,那么线程1必须刷新它的缓存后才能在核心1上获得读写权限,这导致这个缓存行在不同的线程间多次通过L3缓存来交换最新的拷贝数据,这极大的影响了多核心CPU的性能。如果这些CPU核心在不同的插槽上,性能会变得更糟。jvm中优化的方法
CAS算法在JDK中的应用
在原子类变量中,如java.util.concurrent.atomic中的AtomicXXX,都使用了这些底层的JVM支持为数字类型的引用类型提供一种高效的CAS操作,而在java.util.concurrent中的大多数类在实现时都直接或间接的使用了这些原子变量类。
Unsafe
AtomicInteger:
public final int incrementAndGet() {
for (;;) {
int current = get();
int next = current + 1;
if (compareAndSet(current, next))
return next;
}
}
public final boolean compareAndSet(int expect, int update) {
return unsafe.compareAndSwapInt(this, valueOffset, expect, update);
}
Unsafe:
public final native boolean compareAndSwapInt(Object var1, long var2, int var4, int var5);
jdk8u: unsafe.cpp:
cmpxchg = compare and exchange
UNSAFE_ENTRY(jboolean, Unsafe_CompareAndSwapInt(JNIEnv *env, jobject unsafe, jobject obj, jlong offset, jint e, jint x))
UnsafeWrapper("Unsafe_CompareAndSwapInt");
oop p = JNIHandles::resolve(obj);
jint* addr = (jint *) index_oop_from_field_offset_long(p, offset);
return (jint)(Atomic::cmpxchg(x, addr, e)) == e;
UNSAFE_END
jdk8u: atomic_linux_x86.inline.hpp 93行
is_MP = Multi Processor
inline jint Atomic::cmpxchg (jint exchange_value, volatile jint* dest, jint compare_value) {
int mp = os::is_MP();
__asm__ volatile (LOCK_IF_MP(%4) "cmpxchgl %1,(%3)" // ⚠️ cmpxchgl 并不是原子性的指令
: "=a" (exchange_value)
: "r" (exchange_value), "a" (compare_value), "r" (dest), "r" (mp)
: "cc", "memory");
return exchange_value;
}
jdk8u: os.hpp is_MP()
static inline bool is_MP() {
// During bootstrap if _processor_count is not yet initialized
// we claim to be MP as that is safest. If any platform has a
// stub generator that might be triggered in this phase and for
// which being declared MP when in fact not, is a problem - then
// the bootstrap routine for the stub generator needs to check
// the processor count directly and leave the bootstrap routine
// in place until called after initialization has ocurred.
return (_processor_count != 1) || AssumeMP;
}
jdk8u: atomic_linux_x86.inline.hpp
#define LOCK_IF_MP(mp) "cmp $0, " #mp "; je 1f; lock; 1: "
最终实现 🤔
cmpxchg = cas修改变量值(多核需要加lock)
lock cmpxchg 指令
硬件:
lock指令在执行后面指令的时候锁定一个北桥信号(不采用锁总线的方式)
对象在内存中的存储布局
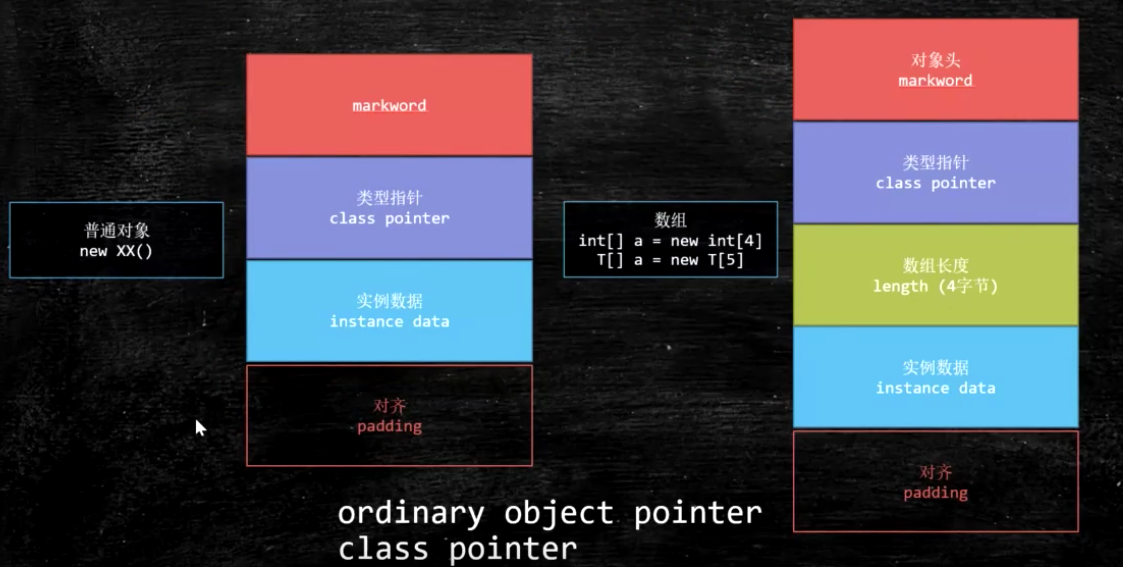
工具:JOL = Java Object Layout
<dependencies>
<!-- https://mvnrepository.com/artifact/org.openjdk.jol/jol-core -->
<dependency>
<groupId>org.openjdk.jol</groupId>
<artifactId>jol-core</artifactId>
<version>0.9</version>
</dependency>
</dependencies>

加锁后:对象头发生变化

synchronized的横切面详解
java源码层级
synchronized(o)
字节码层级
monitorenter moniterexit
JVM层级(Hotspot)
package com.mashibing.insidesync;
import org.openjdk.jol.info.ClassLayout;
public class T01_Sync1 {
public static void main(String[] args) {
Object o = new Object();
System.out.println(ClassLayout.parseInstance(o).toPrintable());
}
}
com.mashibing.insidesync.T01_Sync1$Lock object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 05 00 00 00 (00000101 00000000 00000000 00000000) (5)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 49 ce 00 20 (01001001 11001110 00000000 00100000) (536923721)
12 4 (loss due to the next object alignment)
Instance size: 16 bytes
Space losses: 0 bytes internal + 4 bytes external = 4 bytes total
com.mashibing.insidesync.T02_Sync2$Lock object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 05 90 2e 1e (00000101 10010000 00101110 00011110) (506368005)
4 4 (object header) 1b 02 00 00 (00011011 00000010 00000000 00000000) (539)
8 4 (object header) 49 ce 00 20 (01001001 11001110 00000000 00100000) (536923721)
12 4 (loss due to the next object alignment)
Instance size: 16 bytes
Space losses: 0 bytes internal + 4 bytes external = 4 bytes tota
InterpreterRuntime:: monitorenter方法
IRT_ENTRY_NO_ASYNC(void, InterpreterRuntime::monitorenter(JavaThread* thread, BasicObjectLock* elem))
#ifdef ASSERT
thread->last_frame().interpreter_frame_verify_monitor(elem);
#endif
if (PrintBiasedLockingStatistics) {
Atomic::inc(BiasedLocking::slow_path_entry_count_addr());
}
Handle h_obj(thread, elem->obj());
assert(Universe::heap()->is_in_reserved_or_null(h_obj()),
"must be NULL or an object");
if (UseBiasedLocking) {
// Retry fast entry if bias is revoked to avoid unnecessary inflation
ObjectSynchronizer::fast_enter(h_obj, elem->lock(), true, CHECK);
} else {
ObjectSynchronizer::slow_enter(h_obj, elem->lock(), CHECK);
}
assert(Universe::heap()->is_in_reserved_or_null(elem->obj()),
"must be NULL or an object");
#ifdef ASSERT
thread->last_frame().interpreter_frame_verify_monitor(elem);
#endif
IRT_END
synchronizer.cpp
revoke_and_rebias
void ObjectSynchronizer::fast_enter(Handle obj, BasicLock* lock, bool attempt_rebias, TRAPS) {
if (UseBiasedLocking) {
if (!SafepointSynchronize::is_at_safepoint()) {
BiasedLocking::Condition cond = BiasedLocking::revoke_and_rebias(obj, attempt_rebias, THREAD);
if (cond == BiasedLocking::BIAS_REVOKED_AND_REBIASED) {
return;
}
} else {
assert(!attempt_rebias, "can not rebias toward VM thread");
BiasedLocking::revoke_at_safepoint(obj);
}
assert(!obj->mark()->has_bias_pattern(), "biases should be revoked by now");
}
slow_enter (obj, lock, THREAD) ;
}
void ObjectSynchronizer::slow_enter(Handle obj, BasicLock* lock, TRAPS) {
markOop mark = obj->mark();
assert(!mark->has_bias_pattern(), "should not see bias pattern here");
if (mark->is_neutral()) {
// Anticipate successful CAS -- the ST of the displaced mark must
// be visible <= the ST performed by the CAS.
lock->set_displaced_header(mark);
if (mark == (markOop) Atomic::cmpxchg_ptr(lock, obj()->mark_addr(), mark)) {
TEVENT (slow_enter: release stacklock) ;
return ;
}
// Fall through to inflate() ...
} else
if (mark->has_locker() && THREAD->is_lock_owned((address)mark->locker())) {
assert(lock != mark->locker(), "must not re-lock the same lock");
assert(lock != (BasicLock*)obj->mark(), "don't relock with same BasicLock");
lock->set_displaced_header(NULL);
return;
}
#if 0
// The following optimization isn't particularly useful.
if (mark->has_monitor() && mark->monitor()->is_entered(THREAD)) {
lock->set_displaced_header (NULL) ;
return ;
}
#endif
// The object header will never be displaced to this lock,
// so it does not matter what the value is, except that it
// must be non-zero to avoid looking like a re-entrant lock,
// and must not look locked either.
lock->set_displaced_header(markOopDesc::unused_mark());
ObjectSynchronizer::inflate(THREAD, obj())->enter(THREAD);
}
inflate方法:膨胀为重量级锁
各种锁的介绍
https://www.it610.com/article/1296202395713347584.htm
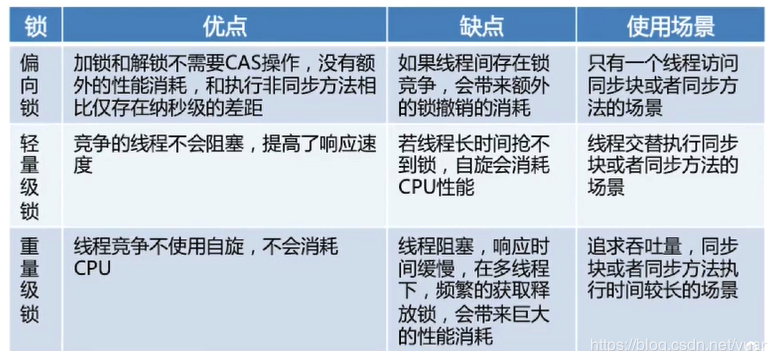
偏向锁
其实没上锁,只是把mark word中贴个了当前线程的id;
偏向锁,顾名思义,它会偏向于第一个访问锁的线程,如果在接下来的运行过程中,该锁没有被其他的线程访问,则持有偏向锁的线程将永远不需要触发同步。
为什么要有偏向锁?
- 多数sychronized方法,在很多情况下,只有一个线程在运行。比如StringBuffer中的一些sync方法。
如果在运行过程中,遇到了其他线程抢占锁,则持有偏向锁的线程会被挂起,JVM会尝试消除它身上的偏向锁,将锁恢复到标准的轻量级锁。(偏向锁只能在单线程下起作用)
轻量级锁
线程在执行同步块之前,会在获取锁的线程的栈上创建一个存储锁记录(Lock Record)的空间,并把对象头里的Mark Word复制到锁记录里(官方成为Displaced Mark Word),然后JVM会使用CAS操作将对象头里的Mark Word更改为指向锁空间的指针。
如果更新成功了就获取到这个对象的轻量级锁,
如果更新失败了首先会检查对象的Mark Word是否指向当前的线程,如果指向当前的线程,说明该线程已经获取这个这个对象的锁了,继续执行同步块代码。
如果不指向当前线程,表示有其他线程竞争锁,当前线程便尝试自旋获取锁。如果在这过程中获取到了,那就执行同步块代码。
如果自旋一定次数还没竞争到锁,就将锁升级为重量级锁,当前线程阻塞。
如果持有线程释放锁失败(CAS替换Mark Word,因为有其他线程在争夺锁),那么将释放锁并唤醒等待的线程
重量级锁
操作系统内核层面。重量级锁是通过互斥量(Mutex)来实现的 ,一个线程获取到锁进入同步块,在没有释放锁之前,会阻塞其他未获取锁的线程。
偏向锁——>轻量级锁
持有线程是持有偏向锁的线程,当前线程是想要获取偏向锁的线程
- 线程第一次访问同步代码块,首先他会检查这个对象的Mark Word中的锁标志位是多少,如果是01,则进入第2步,依此来判断是否是无锁状态或者是偏向锁状态。
- 继续判断是否是偏向锁,如果是偏向锁则进入第3步,如果不是则进入第 步。
- 接着判断对象Mark Word中的Tread ID是否是当前线程ID,如果是就代表当前线程已经获取到这个对象锁,以后再获取对象锁的时候不需要再进行CAS操作, 只会往当前线程的栈中添加一条Displaced Mark Word为空的Lock Record中,用来记录重入的次数。释放锁时依次删除锁空间里的Lock Record,当记录释放完之后就代表着释放了这个对象的锁。 这里有一点需要注意:偏向锁的释放并不是主动,而是被动的,持有偏向锁的线程执行完同步代码后不会主动释放偏向锁,而是等待其他线程来竞争才会释放锁 ,就是Thread ID依旧不会改变。
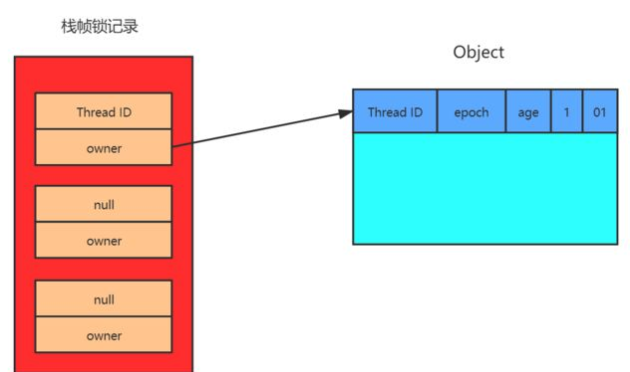
- 如果当前对象Mark Word中的Thread ID不是当前线程,那么就会使用CAS操作修改Thread ID,如果这个对象是匿名偏向状态就可以修改成功,成功获取锁,如果不是就说明对象锁已被其他线程占有,则修改失败,执行第5步。
- 修改失败后就会进行锁撤销,锁的撤销需要等待一个全局安全点(当前没有执行的字节码),然后暂停拥有这个偏向锁的线程,判断这个线程是否依然存活。如果是执行第6步,否则第7步
- 如果持有线程依旧存活,判断是否还在执行同步代码块(根据Lock Record),如果还在执行,则升级为轻量级锁,持有线程获取轻量级锁(JVM将对象Mark Word与Lock Record交换),获取线程CAS竞争获取锁。
- 如果对象已死亡或不在执行同步代码块,则判断该对象是否可重偏向。如果可以则将对象设置成匿名偏向状态,则将使用CAS操作将偏向锁重新指向当前线程,获取到偏向锁,执行同步代码块。如果不可重偏向,就将对象设置为无锁状态,然后升级为轻量级锁,CAS获取锁。
- 恢复暂停的线程,继续执行代码
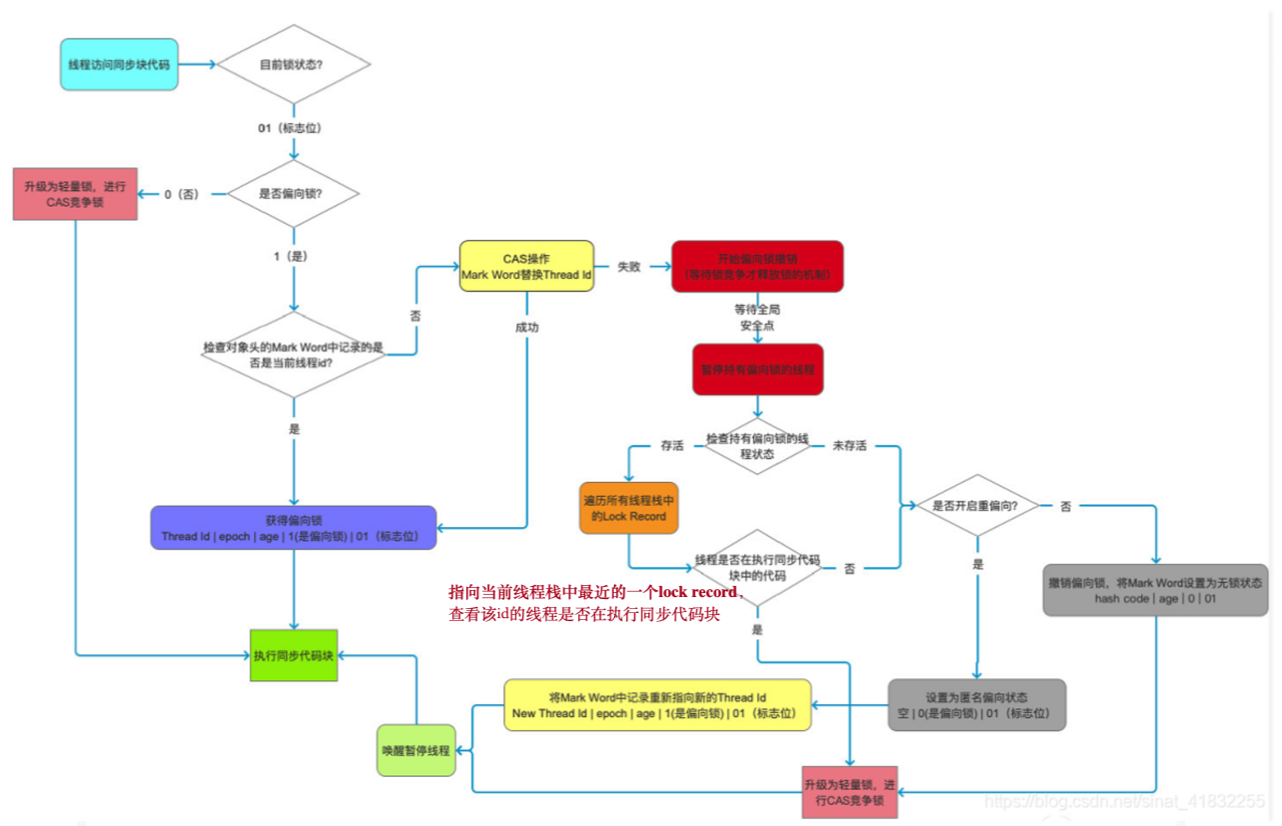
synchronized锁升级过程 🤔
详细过程
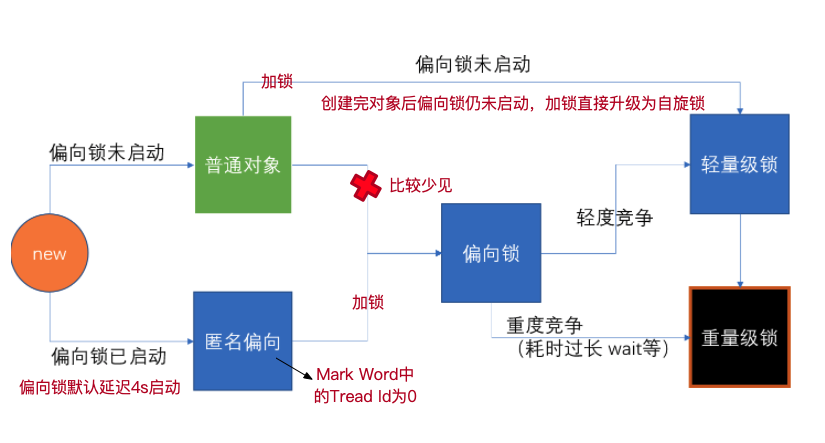
new - 偏向锁 - 轻量级锁 (无锁, 自旋锁,自适应自旋)- 重量级锁
synchronized优化的过程和markword息息相关
用markword中最低的三位代表锁状态 其中1位是偏向锁位 两位是普通锁位
-
Object o = new Object() 锁 = 0 01 无锁态 注意:如果偏向锁打开,默认是匿名偏向状态
-
o.hashCode() 001 + hashcode
00000001 10101101 00110100 00110110 01011001 00000000 00000000 00000000little endian big endian
00000000 00000000 00000000 01011001 00110110 00110100 10101101 00000001
-
默认synchronized(o) 00 -> 轻量级锁 默认情况 偏向锁有个时延,默认是4秒 why? 因为JVM虚拟机自己有一些默认启动的线程,里面有好多sync代码,这些sync代码启动时就知道肯定会有竞争,如果使用偏向锁,就会造成偏向锁不断的进行锁撤销和锁升级的操作,效率较低。
// 偏向锁启动延时 -XX:BiasedLockingStartupDelay=0 -
如果设定上述参数 new Object () - > 101 偏向锁 ->线程ID为0 -> Anonymous BiasedLock 打开偏向锁,new出来的对象,默认就是一个可偏向匿名对象101
-
如果有线程上锁 上偏向锁,指的就是,把markword的线程ID改为自己线程ID的过程 偏向锁不可重偏向 批量偏向 批量撤销
-
如果有线程竞争 撤销偏向锁,升级轻量级锁 线程在自己的线程栈生成LockRecord ,用CAS操作将markword设置为指向自己这个线程的LR的指针,设置成功者得到锁
-
如果竞争加剧 竞争加剧:有线程超过10次自旋, -XX:PreBlockSpin, 或者自旋线程数超过CPU核数的一半, 1.6之后,加入自适应自旋 Adapative Self Spinning , JVM自己控制升级重量级锁:-> 向操作系统申请资源,linux mutex , CPU从3级-0级系统调用,线程挂起,进入等待队列,等待操作系统的调度,然后再映射回用户空间
(以上实验环境是JDK11,打开就是偏向锁,而JDK8默认对象头是无锁)
偏向锁默认是打开的,但是有一个时延,如果要观察到偏向锁,应该设定参数。
关于epoch,普通对象变为偏向锁的过程: (不重要)
批量重偏向与批量撤销渊源:从偏向锁的加锁解锁过程中可看出,当只有一个线程反复进入同步块时,偏向锁带来的性能开销基本可以忽略,但是当有其他线程尝试获得锁时,就需要等到safe point时,再将偏向锁撤销为无锁状态或升级为轻量级,会消耗一定的性能,所以在多线程竞争频繁的情况下,偏向锁不仅不能提高性能,还会导致性能下降。于是,就有了批量重偏向与批量撤销的机制。
原理以class为单位,为每个class维护解决场景批量重偏向(bulk rebias)机制是为了解决:一个线程创建了大量对象并执行了初始的同步操作,后来另一个线程也来将这些对象作为锁对象进行操作,这样会导致大量的偏向锁撤销操作。批量撤销(bulk revoke)机制是为了解决:在明显多线程竞争剧烈的场景下使用偏向锁是不合适的。
一个偏向锁撤销计数器,每一次该class的对象发生偏向撤销操作时,该计数器+1,当这个值达到重偏向阈值(默认20)时,JVM就认为该class的偏向锁有问题,因此会进行批量重偏向。每个class对象会有一个对应的epoch字段,每个处于偏向锁状态对象的Mark Word中也有该字段,其初始值为创建该对象时class中的epoch的值。每次发生批量重偏向时,就将该值+1,同时遍历JVM中所有线程的栈,找到该class所有正处于加锁状态的偏向锁,将其epoch字段改为新值。下次获得锁时,发现当前对象的epoch值和class的epoch不相等,那就算当前已经偏向了其他线程,也不会执行撤销操作,而是直接通过CAS操作将其Mark Word的Thread Id 改成当前线程Id。当达到重偏向阈值后,假设该class计数器继续增长,当其达到批量撤销的阈值后(默认40),JVM就认为该class的使用场景存在多线程竞争,会标记该class为不可偏向,之后,对于该class的锁,直接走轻量级锁的逻辑。
总结
没错,我就是厕所所长
加锁,指的是锁定对象
锁升级的过程
JDK较早的版本 OS的资源 互斥量 用户态 -> 内核态的转换 重量级 效率比较低
现代版本进行了优化
无锁 - 偏向锁 -轻量级锁(自旋锁)-重量级锁
偏向锁 - markword 上记录当前线程指针,下次同一个线程加锁的时候,不需要争用,只需要判断线程指针是否同一个,所以,偏向锁,偏向加锁的第一个线程 。hashCode备份在线程栈上 线程销毁,锁降级为无锁
有争用 - 锁升级为轻量级锁 - 每个线程有自己的LockRecord在自己的线程栈上,用CAS去争用markword的LR的指针,指针指向哪个线程的LR,哪个线程就拥有锁
自旋超过10次,升级为重量级锁 - 如果太多线程自旋 CPU消耗过大,不如升级为重量级锁,进入等待队列(不消耗CPU)-XX:PreBlockSpin
自旋锁在 JDK1.4.2 中引入,使用 -XX:+UseSpinning 来开启。JDK 6 中变为默认开启,并且引入了自适应的自旋锁(适应性自旋锁)。
自适应自旋锁意味着自旋的时间(次数)不再固定,而是由前一次在同一个锁上的自旋时间及锁的拥有者的状态来决定。如果在同一个锁对象上,自旋等待刚刚成功获得过锁,并且持有锁的线程正在运行中,那么虚拟机就会认为这次自旋也是很有可能再次成功,进而它将允许自旋等待持续相对更长的时间。如果对于某个锁,自旋很少成功获得过,那在以后尝试获取这个锁时将可能省略掉自旋过程,直接阻塞线程,避免浪费处理器资源。
偏向锁由于有锁撤销的过程revoke,会消耗系统资源,所以,在锁争用特别激烈的时候,用偏向锁未必效率高。还不如直接使用轻量级锁。
一些问题
自旋锁什么时候升级为重量级锁?
竞争加剧:有线程超过10次自旋, -XX:PreBlockSpin, 或者自旋线程数超过CPU核数的一半, 1.6之后,加入自适应自旋 Adapative Self Spinning , JVM自己控制升级重量级锁:-> 向操作系统申请资源,linux mutex , CPU从3级-0级系统调用,线程挂起,进入等待队列,等待操作系统的调度,然后再映射回用户空间
为什么有自旋锁还需要重量级锁?
自旋是消耗CPU资源的,如果锁的时间长,或者自旋线程多,CPU会被大量消耗
重量级锁有等待队列,所有拿不到锁的进入等待队列,不需要消耗CPU资源
偏向锁是否一定比自旋锁效率高?
不一定,在明确知道会有多线程竞争的情况下,偏向锁肯定会涉及锁撤销(撕掉Mark Word中的Thread ID),所以这时候直接使用自旋锁JVM启动过程,会有很多线程竞争(明确),所以默认情况启动时不打开偏向锁,过一段儿时间再打开
如果计算过对象的hashCode,则对象无法进入偏向状态!
轻量级锁重量级锁的hashCode存在与什么地方?
答案:线程栈中,轻量级锁的LR中,或是代表重量级锁的ObjectMonitor的成员中
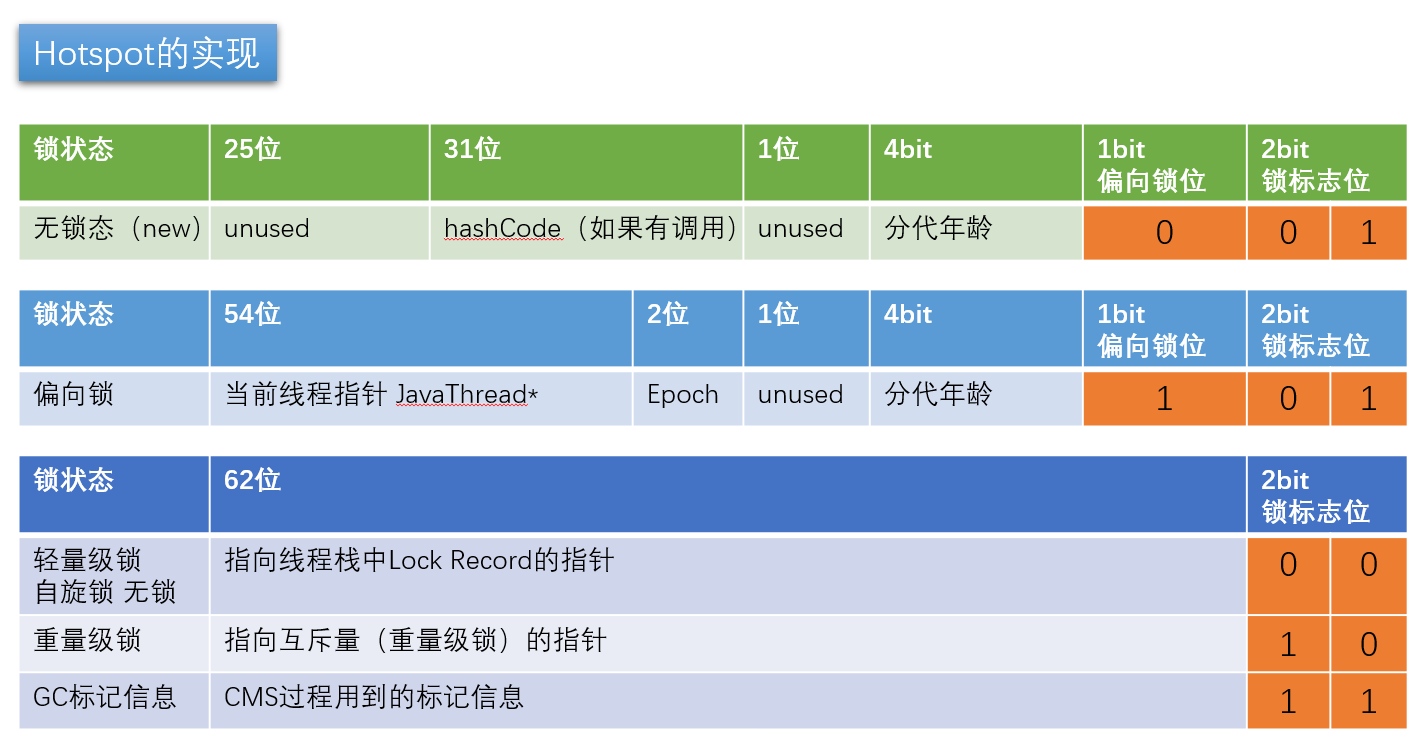
JDK8 markword实现表:
锁重入
sychronized是可重入锁
重入次数必须记录,因为要解锁几次必须得对应
偏向锁 自旋锁 -> 线程栈 -> LR + 1
重量级锁 -> ? ObjectMonitor字段上
synchronized最底层实现
public class T {
static volatile int i = 0;
public static void n() { i++; }
public static synchronized void m() {}
publics static void main(String[] args) {
for(int j=0; j<1000_000; j++) {
m();
n();
}
}
}
java -XX:+UnlockDiagnosticVMOptions -XX:+PrintAssembly T
C1 Compile Level 1 (一级优化)
C2 Compile Level 2 (二级优化)
找到m() n()方法的汇编码,会看到 lock comxchg .....指令
synchronized vs Lock (CAS)
- 存在层面:Syncronized 是Java 中的一个关键字,存在于 JVM 层面,Lock 是 Java 中的一个接口
- 锁的释放条件:1. 获取锁的线程执行完同步代码后,自动释放;2. 线程发生异常时,JVM会让线程释放锁;Lock 必须在 finally 关键字中释放锁,不然容易造成线程死锁
- 锁的获取: 在 Syncronized 中,假设线程 A 获得锁,B 线程等待。如果 A 发生阻塞,那么 B 会一直等待。在 Lock 中,会分情况而定,Lock 中有尝试获取锁的方法,如果尝试获取到锁,则不用一直等待
- 锁的状态:Synchronized 无法判断锁的状态,Lock 则可以判断
- 锁的类型:Synchronized 是可重入,不可中断,非公平锁;Lock 锁则是 可重入,可判断,可公平锁
- 锁的性能:Synchronized 适用于少量同步的情况下,性能开销比较大。Lock 锁适用于大量同步阶段:
- Lock 锁可以提高多个线程进行读的效率(使用 readWriteLock)
- 在竞争不是很激烈的情况下,Synchronized的性能要优于ReetrantLock,但是在资源竞争很激烈的情况下,Synchronized的性能会下降几十倍,但是ReetrantLock的性能能维持常态;
- 如果是线程交替执行的情况下,ReetrantLock其实用不到队列,在jdk级别解决了同步问题。
- ReetrantLock 提供了多样化的同步,比如有时间限制的同步,可以被Interrupt的同步(synchronized的同步是不能Interrupt的)等。
- synchronized到重量级之后是等待队列(不消耗CPU), CAS(等待期间消耗CPU)
性能区别
synchronized是托管给JVM执行的,而lock是java写的控制锁的代码。在Java1.5中,synchronize是性能低效的。因为这是一个重量级操作,需要调用操作接口,导致有可能加锁消耗的系统时间比加锁以外的操作还多。相比之下使用Java提供的Lock对象,性能更高一些。但是到了Java1.6,发生了变化。synchronize在语义上很清晰,可以进行很多优化,有适应自旋,锁消除,锁粗化,轻量级锁,偏向锁等等。导致在Java1.6上synchronize的性能并不比Lock差。官方也表示,他们也更支持synchronize,在未来的版本中还有优化余地。
说到这里,还是想提一下这2中机制的具体区别。据我所知,synchronized原始采用的是CPU悲观锁机制,即线程获得的是独占锁。独占锁意味着其他线程只能依靠阻塞来等待线程释放锁。而在CPU转换线程阻塞时会引起线程上下文切换,当有很多线程竞争锁的时候,会引起CPU频繁的上下文切换导致效率很低。
而Lock用的是乐观锁方式。所谓乐观锁就是,每次不加锁而是假设没有冲突而去完成某项操作,如果因为冲突失败就重试,直到成功为止。乐观锁实现的机制就是CAS操作(Compare and Swap)。我们可以进一步研究ReentrantLock的源代码,会发现其中比较重要的获得锁的一个方法是compareAndSetState。这里其实就是调用的CPU提供的特殊指令。
现代的CPU提供了指令,可以自动更新共享数据,而且能够检测到其他线程的干扰,而 compareAndSet() 就用这些代替了锁定。这个算法称作非阻塞算法,意思是一个线程的失败或者挂起不应该影响其他线程的失败或挂起的算法。
用途区别
synchronized原语和ReentrantLock在一般情况下没有什么区别,但是在非常复杂的同步应用中,请考虑使用ReentrantLock,特别是遇到下面几种需求的时候:
1.某个线程在等待一个锁的控制权的这段时间需要中断
2.需要分开处理一些wait-notify,ReentrantLock里面的Condition应用,能够控制notify哪个线程
3.具有公平锁功能,每个到来的线程都将排队等候
下面细细道来……
先说第一种情况,ReentrantLock的lock机制有2种,忽略中断锁和响应中断锁,这给我们带来了很大的灵活性。比如:如果A、B2个线程去竞争锁,A线程得到了锁,B线程等待,但是A线程这个时候实在有太多事情要处理,就是一直不返回,B线程可能就会等不及了,想中断自己,不再等待这个锁了,转而处理其他事情。这个时候ReentrantLock就提供了2种机制:
第一,B线程中断自己(或者别的线程中断它),但是ReentrantLock不去响应,继续让B线程等待,你再怎么中断,我全当耳边风(synchronized原语就是如此)
第二,B线程中断自己(或者别的线程中断它),ReentrantLock处理了这个中断,并且不再等待这个锁的到来,完全放弃。
锁消除 lock eliminate
public void add(String str1,String str2){
StringBuffer sb = new StringBuffer();
sb.append(str1).append(str2);
}
我们都知道 StringBuffer 是线程安全的,因为它的关键方法都是被 synchronized 修饰过的,但我们看上面这段代码,我们会发现,sb 这个引用只会在 add 方法中使用,不可能被其它线程引用(因为是局部变量,栈私有),因此 sb 是不可能共享的资源,JVM 会自动消除 StringBuffer 对象内部的锁。
锁粗化 lock coarsening
public String test(String str){
int i = 0;
StringBuffer sb = new StringBuffer():
while(i < 100){
sb.append(str);
i++;
}
return sb.toString():
}
JVM 会检测到这样一连串的操作都对同一个对象加锁(while 循环内 100 次执行 append,没有锁粗化的就要进行 100 次加锁/解锁),此时 JVM 就会将加锁的范围粗化到这一连串的操作的外部(比如 while 虚幻体外),使得这一连串操作只需要加一次锁即可。
锁降级(不重要)
https://www.zhihu.com/question/63859501
其实,只被VMThread访问,降级也就没啥意义了。所以可以简单认为锁降级不存在!
超线程
一个ALU + 两组Registers + PC
参考资料
http://openjdk.java.net/groups/hotspot/docs/HotSpotGlossary.html
既已览卷至此,何不品评一二: