SpringCloud Alibaba Seata处理分布式事务
分布式事务问题
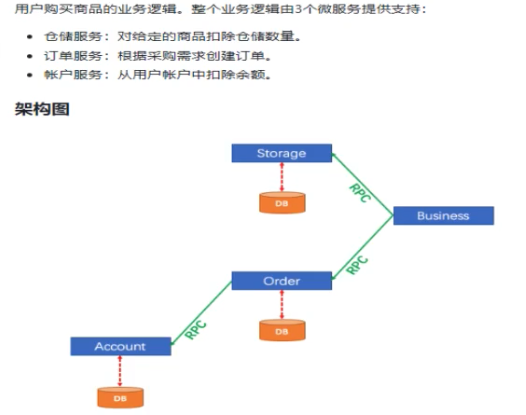
一次业务操作需要跨多个数据源或需要跨多个系统进行远程调用,就会产生分布式事务问题。
单体应用被拆分成微服务应用,原来的三个模块被拆分成三个独立的应用,分别使用三个独立的数据源,业务操作需要调用三个服务来完成。此时每个服务内部的数据一致性由本地事务来保证,但是全局的数据一致性问题没法保证。
Seata简介
Seata是一款开源的分布式事务解决方案,致力于提供高性能和简单易用的分布式事务服务。Seata 将为用户提供了 AT、TCC、SAGA 和 XA 事务模式,为用户打造一站式的分布式解决方案。
分布式事务处理过程
一些术语
-
Transaction ID XID:全局唯一的事务ID
-
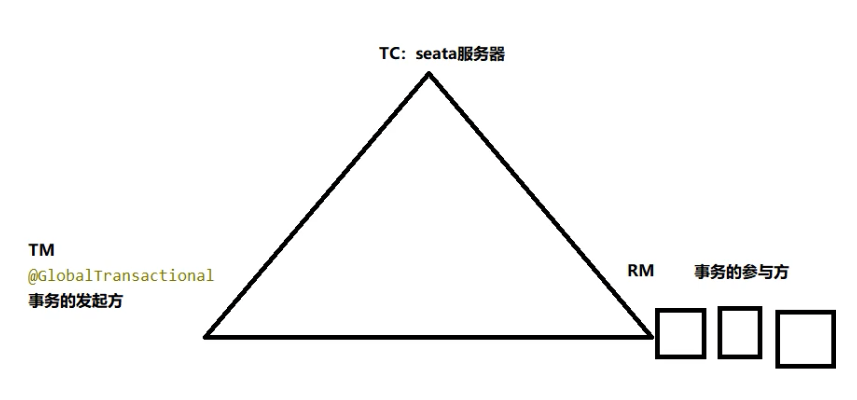
3组件概念:
- Transaction Coordinator(TC) :事务协调器,维护全局事务的运行状态,负责协调并驱动全局事务的提交或回滚;
- Transaction Manager(TM) : 控制全局事务的边界,负责开启一个全局事务,并最终发起全局提交或全局回滚的决议;
- Resource Manager(RM) :控制分支事务,负责分支注册,状态汇报,并接收事务协调器的指令,驱动分支(本地)事务的提交和回滚;
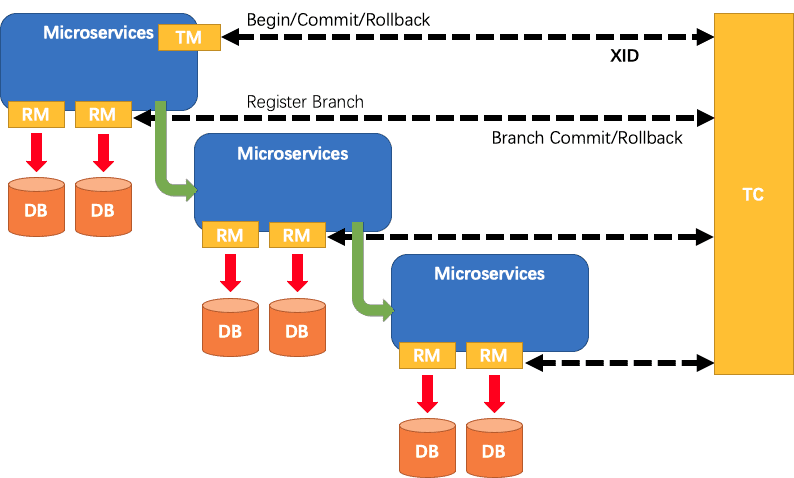
处理过程
- TM向TC申请开启一个全局事务,全局事务创建成功并生成一个全局唯一的XID;
- XID在微服务调用链路的上下文中传播;
- RM向TC注册分支事务,将其纳入XID对应全局事务的管辖;
- TM向TC发起针对XID 的全局提交或回滚决议;
- TC调度XID下管辖的全部分支事务完成提交或回滚请求。
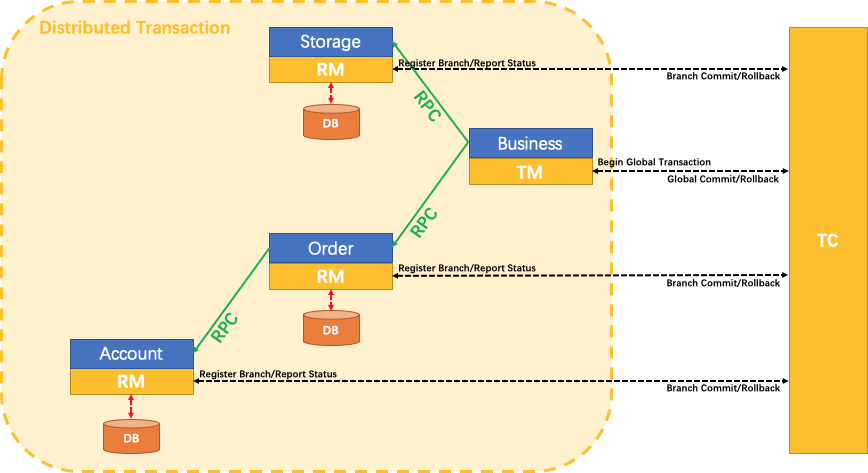
SEATA的分布式交易解决方案
我们只需要使用一个 @GlobalTransactional 注解在业务方法上:
@GlobalTransactional
public void purchase(String userId, String commodityCode, int orderCount) {
......
}
Seata-Server安装
1)seata-server-0.9.0.zip解压到指定目录并修改conf目录下的file.conf配置文件
- 先备份原始file.conf文件
- 主要修改:自定义事务组名称+事务日志存储模式为db+数据库连接信息
############# service 模块配置分组名称 #############
service {
# vgroup->rgroup ⭐️ 此处修改分组名称,名称任意
vgroup_mapping.my_test_tx_group = "fsp_tx_group"
#only support single node
default.grouplist = "127.0.0.1:8091"
#degrade current not support
enableDegrade = false
#disable
disable = false
#unit ms,s,m,h,d represents milliseconds, seconds, minutes, hours, days, default permanent
max.commit.retry.timeout = "-1"
max.rollback.retry.timeout = "-1"
}
############# store 模块配置 存储模式为db+数据库连接信息 #############
store {
## store mode: file、db
mode = "db"
## file store
file {
dir = "sessionStore"
# branch session size , if exceeded first try compress lockkey, still exceeded throws exceptions
max-branch-session-size = 16384
# globe session size , if exceeded throws exceptions
max-global-session-size = 512
# file buffer size , if exceeded allocate new buffer
file-write-buffer-cache-size = 16384
# when recover batch read size
session.reload.read_size = 100
# async, sync
flush-disk-mode = async
}
## database store
db {
## the implement of javax.sql.DataSource, such as DruidDataSource(druid)/BasicDataSource(dbcp) etc.
datasource = "dbcp"
## mysql/oracle/h2/oceanbase etc.
db-type = "mysql"
driver-class-name = "com.mysql.jdbc.Driver"
url = "jdbc:mysql://127.0.0.1:3306/seata"
user = "root"
password = "password"
min-conn = 1
max-conn = 3
global.table = "global_table"
branch.table = "branch_table"
lock-table = "lock_table"
query-limit = 100
}
}
2)数据库新建库seata,建表sql在/seata-server-0.9.0/seata/conf/db_store.sql文件中
3)修改seata-server-0.9.0/seata/conf目录下的 registry.conf 配置文件
registry {
# 指明注册中心为nacos
type = "nacos"
nacos {
serverAddr = "localhost:8848"
namespace = ""
cluster = "default"
}
...
4)先启动Nacos端口号8848
5)再启动seata-server
./Users/silince/Applications/Seata/seata/bin/seata-server.sh
订单/库存/账户业务数据库准备
以下演示都需要先启动Nacos后启动Seata,保证两个都OK
1)分布式事务业务说明
这里我们会创建三个服务,一个订单服务,一个库存服务,一个账户服务:
- 当用户下单时,会在订单服务中创建一个订单,然后通过远程调用库存服务来扣减下单商品的库存
- 再通过远程调用账户服务来扣减用户账户里面的余额,
- 最后在订单服务中修改订单状态为已完成。
该操作跨越三个数据库,有两次远程调用,很明显会有分布式事务问题。
2)创建业务数据库
CREATE DATABASE seata_order; -- 存储订单的数据库
CREATE DATABASE seata_storage;-- 存储库存的数据库
CREATE DATABASE seata_account;-- 存储账户信息的数据库
3)按照上述3库分别建对应业务表
seata_order库下建t_order表
CREATE TABLE t_order(
`id` BIGINT(11) NOT NULL AUTO_INCREMENT PRIMARY KEY,
`user_id` BIGINT(11) DEFAULT NULL COMMENT '用户id',
`product_id` BIGINT(11) DEFAULT NULL COMMENT '产品id',
`count` INT(11) DEFAULT NULL COMMENT '数量',
`money` DECIMAL(11,0) DEFAULT NULL COMMENT '金额',
`status` INT(1) DEFAULT NULL COMMENT '订单状态:0:创建中; 1:已完结'
) ENGINE=INNODB AUTO_INCREMENT=7 DEFAULT CHARSET=utf8;
SELECT * FROM t_order;
seata_storage库下建t_storage表
CREATE TABLE t_storage(
`id` BIGINT(11) NOT NULL AUTO_INCREMENT PRIMARY KEY,
`product_id` BIGINT(11) DEFAULT NULL COMMENT '产品id',
`total` INT(11) DEFAULT NULL COMMENT '总库存',
`used` INT(11) DEFAULT NULL COMMENT '已用库存',
`residue` INT(11) DEFAULT NULL COMMENT '剩余库存'
) ENGINE=INNODB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8;
INSERT INTO seata_storage.t_storage(`id`,`product_id`,`total`,`used`,`residue`)
VALUES('1','1','100','0','100');
SELECT * FROM t_storage;
seata_account库下建t_account表
CREATE TABLE t_account(
`id` BIGINT(11) NOT NULL AUTO_INCREMENT PRIMARY KEY COMMENT 'id',
`user_id` BIGINT(11) DEFAULT NULL COMMENT '用户id',
`total` DECIMAL(10,0) DEFAULT NULL COMMENT '总额度',
`used` DECIMAL(10,0) DEFAULT NULL COMMENT '已用余额',
`residue` DECIMAL(10,0) DEFAULT '0' COMMENT '剩余可用额度'
) ENGINE=INNODB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8;
INSERT INTO seata_account.t_account(`id`,`user_id`,`total`,`used`,`residue`) VALUES('1','1','1000','0','1000')
SELECT * FROM t_account;
4)按照上述3库分别建对应的回滚日志表
- 订单-库存-账户3个库下都需要建各自的回滚日志表
/seata-server-0.9.0/seata/conf目录下的db_undo_log.sql
drop table `undo_log`;
CREATE TABLE `undo_log` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`branch_id` bigint(20) NOT NULL,
`xid` varchar(100) NOT NULL,
`context` varchar(128) NOT NULL,
`rollback_info` longblob NOT NULL,
`log_status` int(11) NOT NULL,
`log_created` datetime NOT NULL,
`log_modified` datetime NOT NULL,
`ext` varchar(100) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `ux_undo_log` (`xid`,`branch_id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
5)准备后的最终结果
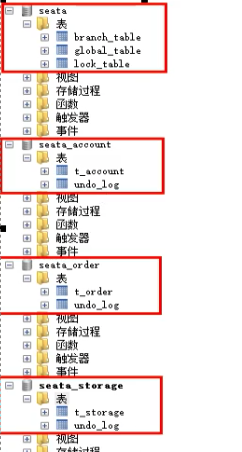
订单/库存/账户业务微服务准备
新建订单Order-Module
-
POM 注意排除掉springcloud中自带的seata,更换为自己版本的seata
<!--seata--> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-seata</artifactId> <exclusions> <exclusion> <artifactId>seata-all</artifactId> <groupId>io.seata</groupId> </exclusion> </exclusions> </dependency> <dependency> <groupId>io.seata</groupId> <artifactId>seata-all</artifactId> <version>0.9.0</version> </dependency> -
YML 注意自定义事务组名称需要与seata-server中的对应
-
file.conf
-
registry.conf
-
domain
- Order
- CommonResult
-
Dao接口及实现
- OrderDao
- resources文件夹下新建mapper文件夹后添加 OrderMapper.xml
-
Service接口及实现
- StorageService
- AccountService
-
Controller
-
Config配置
- DataSourceProxyConfig
- MybatisConfig
-
主启动类
新建库存Storage-Module
新建账户Account-Module
测试
1)正常下单 :http://localhost:2001/order/create?userid=1&producrid=1&counr=10&money=100
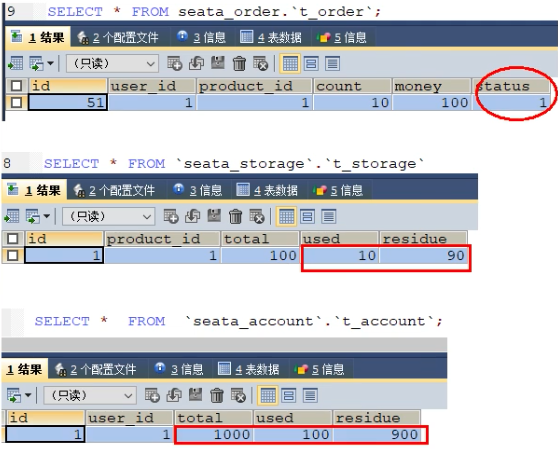
2)设置超时异常,没加@GlobalTransactional
在AccountServiceImpl添加超时
/**
* 扣减账户余额
*/
@Override
public void decrease(Long userId, BigDecimal money) {
LOGGER.info("------->account-service中扣减账户余额开始");
//模拟超时异常,全局事务回滚
//暂停几秒钟线程
try { TimeUnit.SECONDS.sleep(20); } catch (InterruptedException e) { e.printStackTrace(); }
accountDao.decrease(userId,money);
LOGGER.info("------->account-service中扣减账户余额结束");
}
故障情况:
- 当库存和账户余额扣减后,订单状态并没有设置为已经完成,没有从零改为1
- 而且由于feign的重试机制,账户余额还有可能被多次扣减
3)设置超时异常,在业务入口添加 @GlobalTransactional 注解:
- 下单后数据库数据并没有任何改变,记录都添加不进来
/**
* 创建订单->调用库存服务扣减库存->调用账户服务扣减账户余额->修改订单状态
* 简单说:下订单->扣库存->减余额->改状态
*/
@Override
@GlobalTransactional(name = "fsp=create=order",rollbackFor = Exception.class) // name随便取
public void create(Order order) {
// 1 新建订单
log.info("------> 开始新建订单");
orderDao.create(order);
log.info("------> 订单微服务开始调用库存,做扣减Count");
// 2 扣减库存
storageService.decrease(order.getProductId(),order.getCount());
log.info("------> 订单微服务开始调用库存,做扣减end");
log.info("------> 订单微服务开始调用账户,做扣减Money");
// 3 扣减账户
accountService.decrease(order.getUserId(),order.getMoney());
log.info("------> 订单微服务开始调用账户,做扣减end");
//4. 修改订单的状态,从0到1,1代表已经完成
log.info("------> 修改订单状态开始");
orderDao.update(order.getUserId(),0);
log.info("------> 修改订单状态结束");
log.info("------> 下订单结束 😄");
}
Seata原理
2019年1月份蚂蚁金服和阿里巴巴共同开源的分布式事务解决方案
Simple Extensible Autonomous Transaction Architecture,简单可扩展自治事务框架
2020起初,参加工作后用1.0以后的版本,如 v1.0.0-GA。 0.9不支持集群。
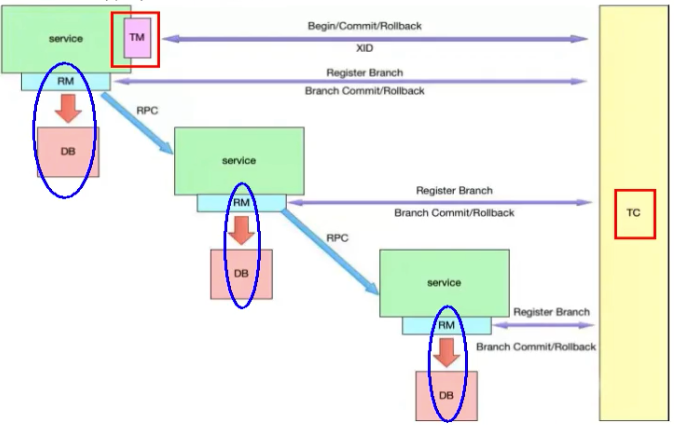
再看TC/TM/RM三大组件
分布式事务的执行流程:
- TM开启分布式事务(TM向TC注册全局事务记录)
- 换业务场景,编排数据库,服务等事务内资源(RM向TC汇报资源准备状态)
- TM结束分布式事务,事务一阶段结束(TM通知TC提交/回滚分布式事务)
- TC汇总事务信息,决定分布式事务是提交还是回滚
- TC通知所有RM提交/回滚资源,事务二阶段结束。
AT模式如何做到对业务的无侵入
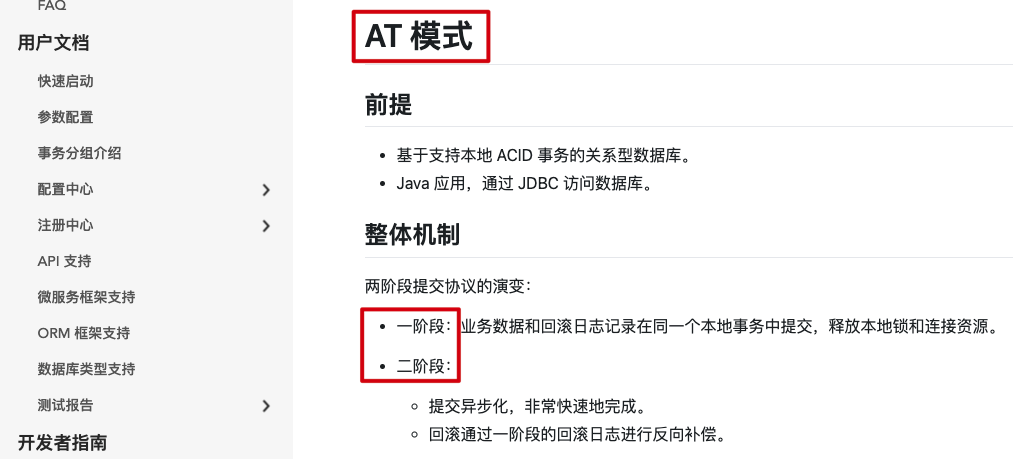
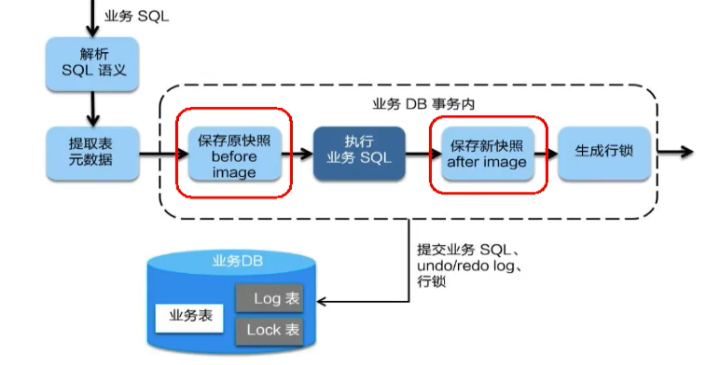
一阶段加载
在一阶段,Seata会拦截业务 SQL,
- 解析SQL语义,找到
业务 SQL要更新的业务数据,在业务数据被更新前,将其保存成before image - 执行“业务 SQL”更新业务数据,在业务数据更新之后,
- 其保存成
after image,最后生成行锁。
以上操作全部在一个数据库事务内完成,这样保证了一阶段操作的原子性。
二阶段提交
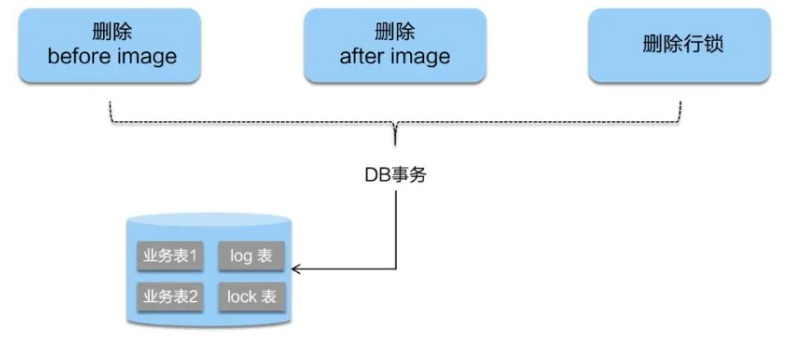
二阶段如是顺利提交的话,
因为“业务 SQL”在一阶段已经提交至数据库,所以Seata框架只需将一阶段保存的快照数据和行锁删掉,完成数据清理即可。
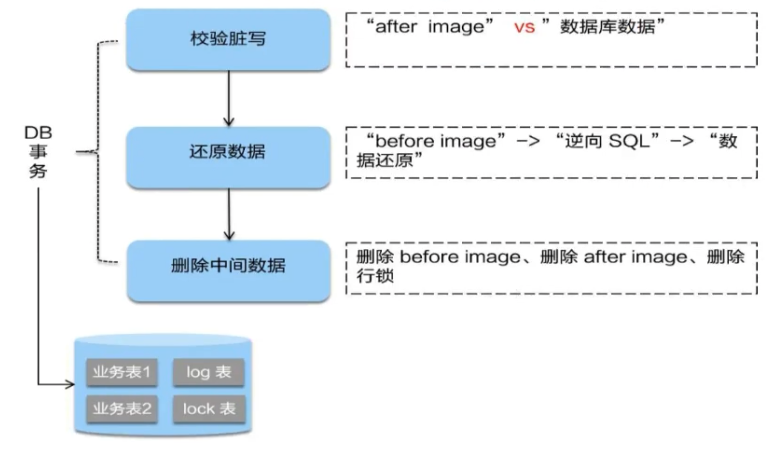
二阶段回滚
二阶段如果是回滚的话,Seata 就需要回滚一阶段已经执行的 业务 SQL,还原业务数据。
回滚方式便是用 before image 还原业务数据;但在还原前要首先要校验脏写,对比数据库当前业务数据”和 after image如果两份数据完全一致就说明没有脏写,可以还原业务数据,如果不一致就说明有脏写,出现脏写就需要转人工处理。
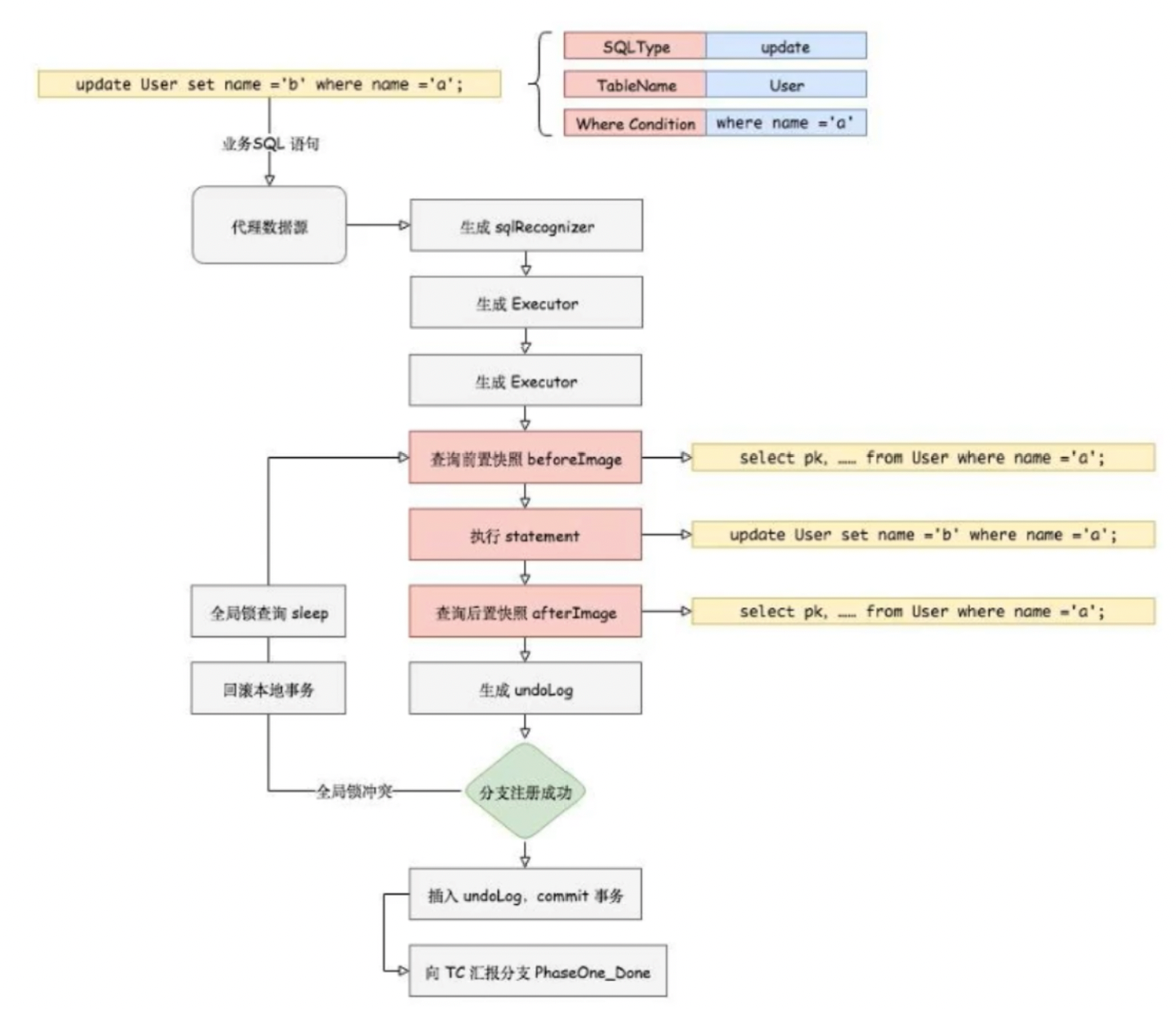
补充
既已览卷至此,何不品评一二: