JVM参数调优与内存溢出OOM
JVM参数调优
前言
你说你做过JVM调优和参数配置,请问如何盘点查看JVM系统默认值
使用jps和jinfo进行查看
-Xms:初始堆空间
-Xmx:堆最大值
-Xss:栈空间
-Xms 和 -Xmx最好调整一致,防止JVM频繁进行收集和回收
JVM参数类型 🤔
- 标配参数(从JDK1.0 - Java12都在,很稳定)
- -version
- -help
- java -showversion
- X参数(了解)
- -Xint:解释执行
- -Xcomp:第一次使用就编译成本地代码
- -Xmixed:混合模式
- XX参数(重点)
- Boolean类型
- 公式:
-XX:+ 或者-某个属性+表示开启,-表示关闭 - Case:
-XX:-PrintGCDetails:表示关闭了GC详情输出
- 公式:
- key-value类型
- 公式:
-XX:属性key=属性value - 不满意初始值,可以通过下列命令调整
- case:如何:
-XX:MetaspaceSize=21807104:查看Java元空间的值
- 公式:
- Boolean类型
查看运行的Java程序,JVM参数是否开启,具体值为多少?
首先我们运行一个HelloGC的java程序
public class HelloGC {
public static void main(String[] args) throws InterruptedException {
System.out.println("hello GC");
Thread.sleep(Integer.MAX_VALUE);
}
}
⚠️ 然后使用下列命令查看它的默认参数
jps:查看java的后台进程
jinfo:查看正在运行的java程序
具体使用:
jps -l 得到进程号
12608 com.moxi.interview.study.GC.HelloGC
15200 sun.tools.jps.Jps
15296 org.jetbrains.idea.maven.server.RemoteMavenServer36
4528
12216 org.jetbrains.jps.cmdline.Launcher
9772 org.jetbrains.kotlin.daemon.KotlinCompileDaemon
查看到HelloGC的进程号为:12608
我们使用jinfo -flag 然后查看是否开启PrintGCDetails这个参数
jinfo -flag PrintGCDetails 12608
得到的内容为
-XX:-PrintGCDetails
上面提到了,-号表示关闭,即没有开启PrintGCDetails这个参数
下面我们需要在启动HelloGC的时候,增加 PrintGCDetails这个参数,需要在运行程序的时候配置JVM参数
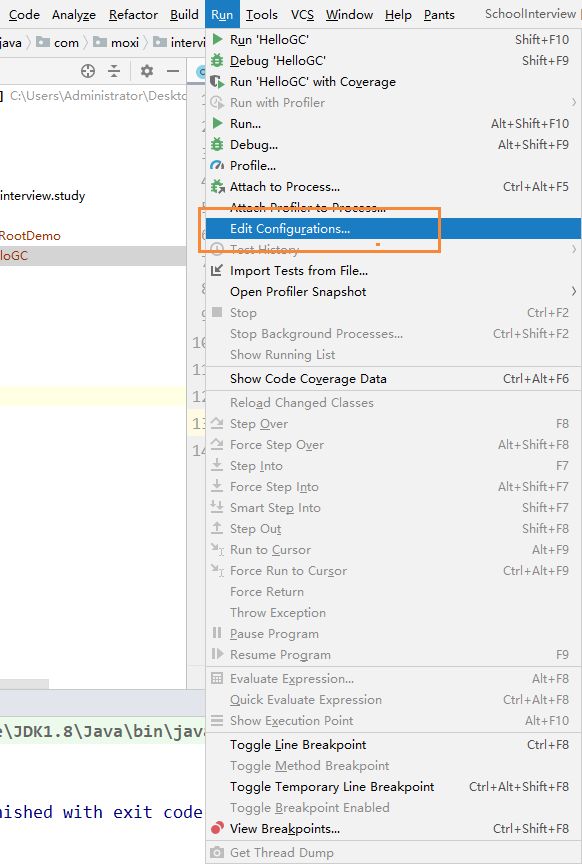
然后在VM Options中加入下面的代码,现在+号表示开启
-XX:+PrintGCDetails
然后在使用jinfo查看我们的配置
jps -l
jinfo -flag PrintGCDetails 13540
得到的结果为
-XX:+PrintGCDetails
我们看到原来的-号变成了+号,说明我们通过 VM Options配置的JVM参数已经生效了
使用下列命令,会把jvm的全部默认参数输出
jinfo -flags ***
题外话(坑题)🤔
两个经典参数:-Xms 和 -Xmx,这两个参数 如何解释
这两个参数,还是属于XX参数,因为取了别名
- -Xms 等价于
-XX:InitialHeapSize:初始化堆内存(默认只会用最大物理内存的64分1) - -Xmx 等价于
-XX:MaxHeapSize:最大堆内存(默认只会用最大物理内存的4分1)
查看JVM默认参数
-
-XX:+PrintFlagsInitial
- 主要是查看初始默认值
- 公式
java -XX:+PrintFlagsInitial -version额外打印版本号java -XX:+PrintFlagsInitial(重要参数,查看参数盘点家底)
-
-XX:+PrintFlagsFinal:主要查看修改更新
java -XX:+PrintFlagsFinal -version会将JVM的各个结果都进行打印;如果有 ` :=表示修改过的,=` 表示没有修改过的java -XX:+printFlagsFinal -Xss128k T(运行的java类名字)运行java命令的同时打印出参数
-
+XX:+PrintCommandLineFlags 打印命令行参数,可以方便的查看垃圾回收器
工作中常用的JVM基本配置参数
查看堆内存
查看JVM的初始化堆内存 -Xms 和最大堆内存 Xmx (必须配置成一样)
public class HelloGC {
public static void main(String[] args) throws InterruptedException {
// 返回Java虚拟机中内存的总量
long totalMemory = Runtime.getRuntime().totalMemory();
// 返回Java虚拟机中试图使用的最大内存量
long maxMemory = Runtime.getRuntime().maxMemory();
System.out.println("TOTAL_MEMORY(-Xms) = " + totalMemory + "(字节)、" + (totalMemory / (double)1024 / 1024) + "MB");
System.out.println("MAX_MEMORY(-Xmx) = " + maxMemory + "(字节)、" + (maxMemory / (double)1024 / 1024) + "MB");
}
}
运行结果为:
TOTAL_MEMORY(-Xms) = 257425408(字节)、245.5MB
MAX_MEMORY(-Xmx) = 3790077952(字节)、3614.5MB
-Xms 初始堆内存为:物理内存的1/64 -Xmx 最大堆内存为:系统物理内存的 1/4
打印JVM默认参数
使用 -XX:+PrintCommandLineFlags 打印出JVM的默认的简单初始化参数
比如我的机器输出为:
-XX:InitialHeapSize=266376000 -XX:MaxHeapSize=4262016000 -XX:+PrintCommandLineFlags -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:-UseLargePagesIndividualAllocation -XX:+UseParallelGC
典型设置案例
-Xms128m -Xmx4096m -Xss1024K -XX:MetaspaceSize=512m -XX:+PrintCommandLineFlags -XX:+PrintGCDetails -XX:+UseSerialGC
生活常用调优参数 ⚠️
-
-Xms:初始化堆内存,默认为物理内存的1/64,等价于 -XX:initialHeapSize
-
-Xmx:最大堆内存,默认为物理内存的1/4,等价于-XX:MaxHeapSize
-
-Xss:设计单个线程栈的大小,一般默认为512K~1024K,等价于 -XX:ThreadStackSize
- 使用 jinfo -flag ThreadStackSize 会发现 -XX:ThreadStackSize = 0
- 这个值的大小是取决于平台的
- Linux/x64:1024KB
- OS X:1024KB
- Oracle Solaris:1024KB
- Windows:取决于虚拟内存的大小
-
-Xmn:设置年轻代大小(一般不需要设置)
-
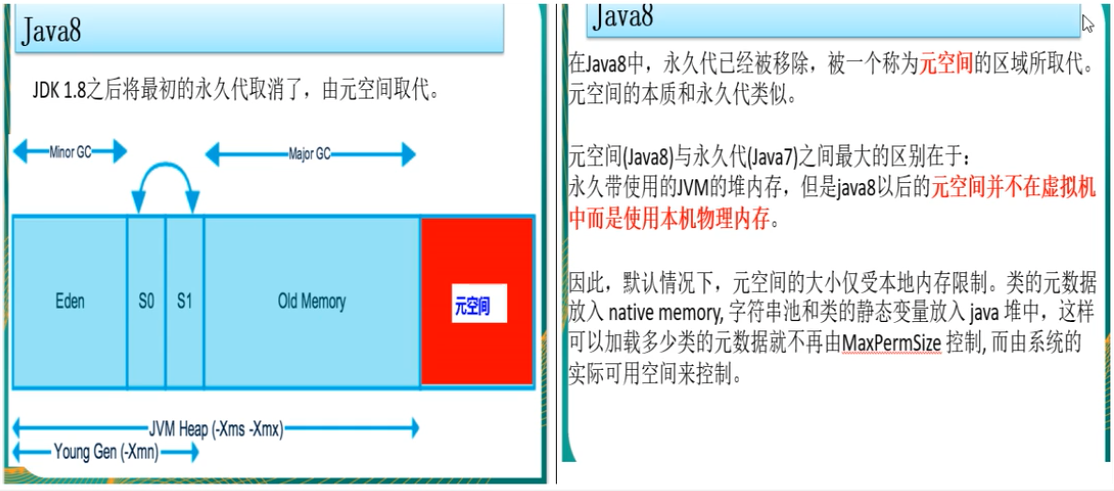
-XX:MetaspaceSize:设置元空间大小
- 元空间的本质和永久代类似,都是对JVM规范中方法区的实现,不过元空间与永久代之间最大的区别在于:元空间并不在虚拟机中,而是使用本地内存,因此,默认情况下,元空间的大小仅受本地内存限制。
-Xms10m -Xmx10m -XX:MetaspaceSize=1024m -XX:+PrintFlagsFinal- 但是默认的元空间大小:只有20多M
- 为了防止在频繁的实例化对象的时候,让元空间出现OOM,因此可以把元空间设置的大一些
-XX:PrintGCDetails
输出详细GC收集日志信息
- GC
- Full GC
GC日志收集流程图
我们使用一段代码,制造出垃圾回收的过程
首先我们设置一下程序的启动配置: 设置初始堆内存为10M,最大堆内存为10M
-Xms10m -Xmx10m -XX:+PrintGCDetails
然后用下列代码,创建一个 非常大空间的byte类型数组
byte [] byteArray = new byte[50 * 1024 * 1024];
运行后,发现会出现下列错误,这就是OOM:java内存溢出,也就是堆空间不足
Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
at com.moxi.interview.study.GC.HelloGC.main(HelloGC.java:22)
同时还打印出了GC垃圾回收时候的详情
[GC (Allocation Failure) [PSYoungGen: 1972K->504K(2560K)] 1972K->740K(9728K), 0.0156109 secs] [Times: user=0.00 sys=0.00, real=0.03 secs]
[GC (Allocation Failure) [PSYoungGen: 504K->480K(2560K)] 740K->772K(9728K), 0.0007815 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[Full GC (Allocation Failure) [PSYoungGen: 480K->0K(2560K)] [ParOldGen: 292K->648K(7168K)] 772K->648K(9728K), [Metaspace: 3467K->3467K(1056768K)], 0.0080505 secs] [Times: user=0.00 sys=0.00, real=0.01 secs]
[GC (Allocation Failure) [PSYoungGen: 0K->0K(2560K)] 648K->648K(9728K), 0.0003035 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[Full GC (Allocation Failure) [PSYoungGen: 0K->0K(2560K)] [ParOldGen: 648K->630K(7168K)] 648K->630K(9728K), [Metaspace: 3467K->3467K(1056768K)], 0.0058502 secs] [Times: user=0.00 sys=0.00, real=0.01 secs]
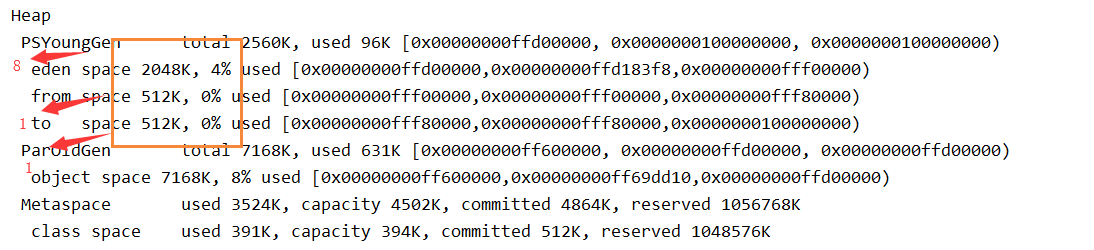
Heap
PSYoungGen total 2560K, used 80K [0x00000000ffd00000, 0x0000000100000000, 0x0000000100000000)
eden space 2048K, 3% used [0x00000000ffd00000,0x00000000ffd143d8,0x00000000fff00000)
from space 512K, 0% used [0x00000000fff00000,0x00000000fff00000,0x00000000fff80000)
to space 512K, 0% used [0x00000000fff80000,0x00000000fff80000,0x0000000100000000)
ParOldGen total 7168K, used 630K [0x00000000ff600000, 0x00000000ffd00000, 0x00000000ffd00000)
object space 7168K, 8% used [0x00000000ff600000,0x00000000ff69dbd0,0x00000000ffd00000)
Metaspace used 3510K, capacity 4500K, committed 4864K, reserved 1056768K
class space used 389K, capacity 392K, committed 512K, reserved 1048576K
问题发生的原因:
因为们通过 -Xms10m 和 -Xmx10m 只给Java堆栈设置了10M的空间,但是创建了50M的对象,因此就会出现空间不足,而导致出错
同时在垃圾收集的时候,我们看到有两个对象:GC 和 Full GC
GC垃圾收集
GC在新生区
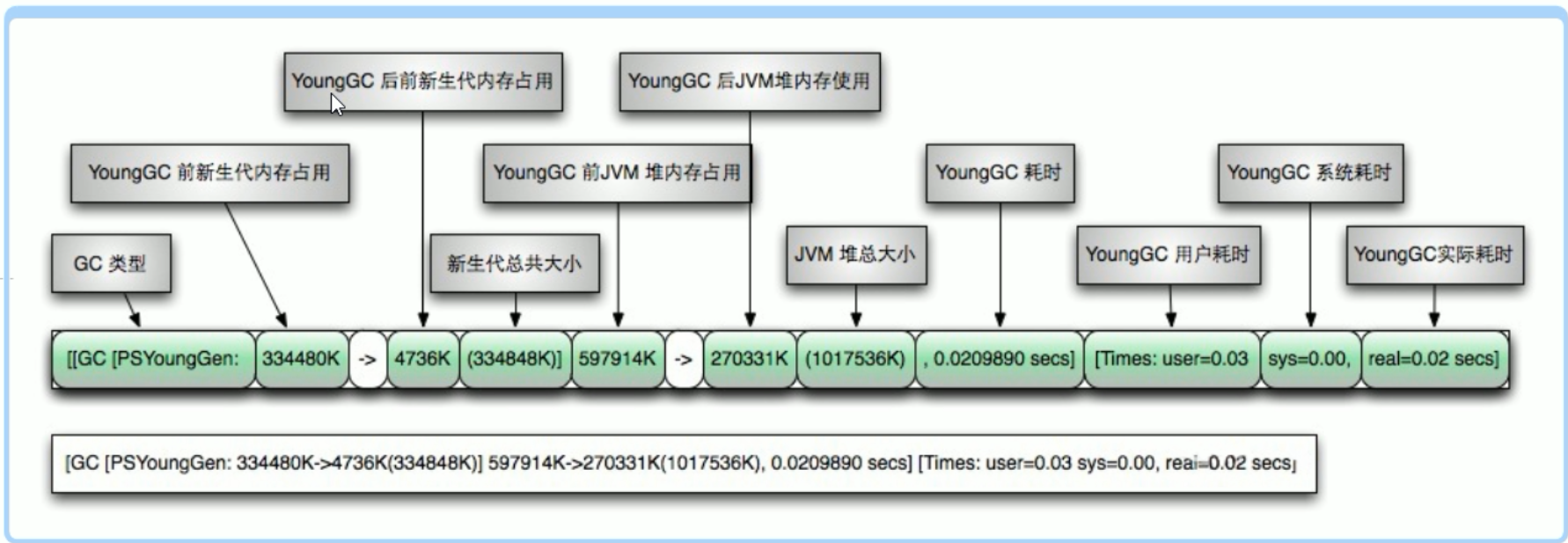
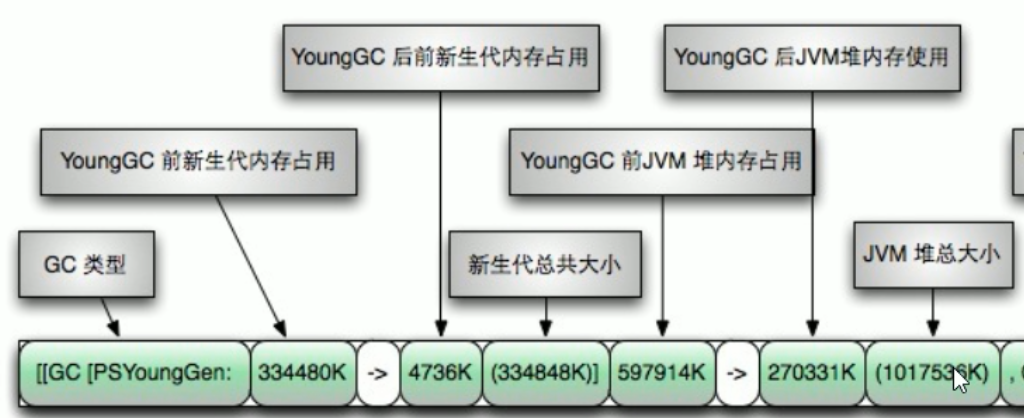
[GC (Allocation Failure) [PSYoungGen: 1972K->504K(2560K)] 1972K->740K(9728K), 0.0156109 secs] [Times: user=0.00 sys=0.00, real=0.03 secs]
GC (Allocation Failure):表示分配失败,那么就需要触发年轻代空间中的内容被回收
[PSYoungGen: 1972K->504K(2560K)] 1972K->740K(9728K), 0.0156109 secs]
参数对应的图为:
Full GC垃圾回收
Full GC大部分发生在养老区
[Full GC (Allocation Failure) [PSYoungGen: 0K->0K(2560K)] [ParOldGen: 648K->630K(7168K)] 648K->630K(9728K), [Metaspace: 3467K->3467K(1056768K)], 0.0058502 secs] [Times: user=0.00 sys=0.00, real=0.01 secs]
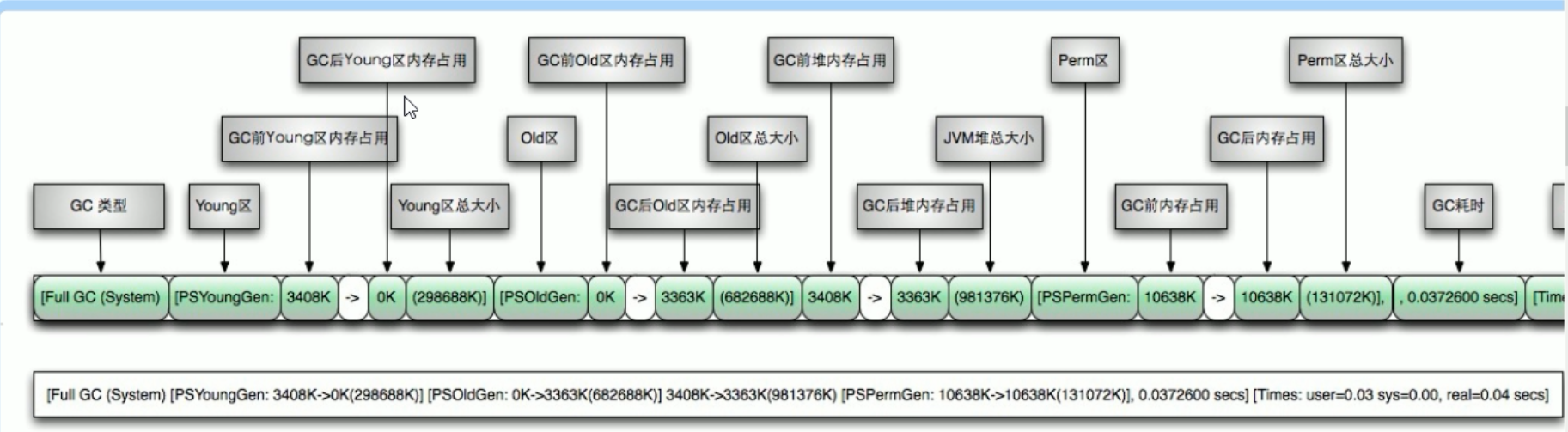
规律:
[名称: GC前内存占用 -> GC后内存占用 (该区内存总大小)]
当我们出现了老年代都扛不住的时候,就会出现OOM异常
-XX:SurvivorRatio
调节新生代中 eden 和 S0、S1的空间比例,默认为 -XX:SuriviorRatio=8,Eden:S0:S1 = 8:1:1
加入设置成 -XX:SurvivorRatio=4,则为 Eden:S0:S1 = 4:1:1
SurvivorRatio值就是设置eden区的比例占多少,S0和S1相同
Java堆从GC的角度还可以细分为:新生代(Eden区,From Survivor区合To Survivor区)和老年代

- eden、SurvivorFrom复制到SurvivorTo,年龄 + 1
首先,当Eden区满的时候会触发第一次GC,把还活着的对象拷贝到SurvivorFrom去,当Eden区再次触发GC的时候会扫描Eden区合From区域,对这两个区域进行垃圾回收,经过这次回收后还存活的对象,则直接复制到To区域(如果对象的年龄已经到达老年的标准,则赋值到老年代区),通知把这些对象的年龄 + 1
- 清空eden、SurvivorFrom
然后,清空eden,SurvivorFrom中的对象,也即复制之后有交换,谁空谁是to
- SurvivorTo和SurvivorFrom互换
最后,SurvivorTo和SurvivorFrom互换,原SurvivorTo成为下一次GC时的SurvivorFrom区,部分对象会在From和To区域中复制来复制去,如此交换15次(由JVM参数MaxTenuringThreshold决定,这个参数默认为15),最终如果还是存活,就存入老年代
-XX:NewRatio(了解)
配置年轻代new 和老年代old 在堆结构的占比
默认: -XX:NewRatio=2 新生代占1,老年代2,年轻代占整个堆的1/3
假如-XX:NewRatio=4:新生代占1,老年代占4,年轻代占整个堆的1/5,NewRadio值就是设置老年代的占比,剩下的1个新生代
新生代特别小,会造成频繁的进行GC收集
-XX:MaxTenuringThreshold
设置垃圾最大年龄,SurvivorTo和SurvivorFrom互换,原SurvivorTo成为下一次GC时的SurvivorFrom区,部分对象会在From和To区域中复制来复制去,如此交换15次(由JVM参数MaxTenuringThreshold决定,这个参数默认为15),最终如果还是存活,就存入老年代
这里就是调整这个次数的,默认是15,并且设置的值 在 0~15之间
查看默认进入老年代年龄:jinfo -flag MaxTenuringThreshold 17344
-XX:MaxTenuringThreshold=0:设置垃圾最大年龄。如果设置为0的话,则年轻对象不经过Survivor区,直接进入老年代。对于年老代比较多的应用,可以提高效率。如果将此值设置为一个较大的值,则年轻代对象会在Survivor区进行多次复制,这样可以增加对象再年轻代的存活时间,增加在年轻代即被回收的概念
Java内存溢出OOM
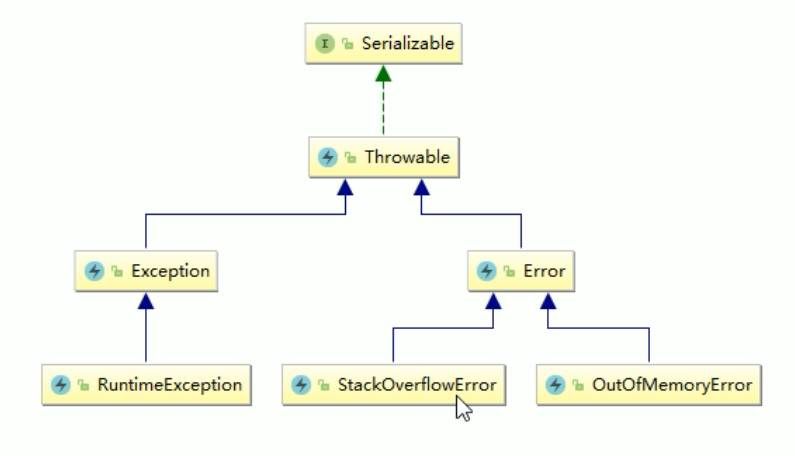
经典错误
JVM中常见的两个错误
StackoverFlowError :栈溢出
OutofMemoryError: java heap space:堆溢出
除此之外,还有以下的错误
- java.lang.StackOverflowError
- java.lang.OutOfMemoryError:java heap space
- java.lang.OutOfMemoryError:GC overhead limit exceeeded
- java.lang.OutOfMemoryError:Direct buffer memory
- java.lang.OutOfMemoryError:unable to create new native thread
- java.lang.OutOfMemoryError:Metaspace
架构
OutOfMemoryError和StackOverflowError是属于Error,不是Exception
StackoverFlowError
堆栈溢出,我们有最简单的一个递归调用,就会造成堆栈溢出,也就是深度的方法调用
栈一般是512K,不断的深度调用,直到栈被撑破
public class StackOverflowErrorDemo {
public static void main(String[] args) {
stackOverflowError();
}
/**
* 栈一般是512K,不断的深度调用,直到栈被撑破
* Exception in thread "main" java.lang.StackOverflowError
*/
private static void stackOverflowError() {
stackOverflowError();
}
}
运行结果
Exception in thread "main" java.lang.StackOverflowError
at com.moxi.interview.study.oom.StackOverflowErrorDemo.stackOverflowError(StackOverflowErrorDemo.java:17)
OutOfMemoryError
java heap space
创建了很多对象,导致堆空间不够存储
/**
* Java堆内存不足
*/
public class JavaHeapSpaceDemo {
public static void main(String[] args) {
// 堆空间的大小 -Xms10m -Xmx10m
// 创建一个 80M的字节数组
byte [] bytes = new byte[80 * 1024 * 1024];
}
}
我们创建一个80M的数组,会直接出现Java heap space
Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
GC overhead limit exceeded
GC回收时间过长时会抛出OutOfMemoryError,过长的定义是,超过了98%的时间用来做GC,并且回收了不到2%的堆内存
连续多次GC都只回收了不到2%的极端情况下,才会抛出。假设不抛出GC overhead limit 错误会造成什么情况呢?
那就是GC清理的这点内存很快会再次被填满,迫使GC再次执行,这样就形成了恶性循环,CPU的使用率一直都是100%,而GC却没有任何成果。

代码演示:
为了更快的达到效果,我们首先需要设置JVM启动参数
-Xms10m -Xmx10m -XX:+PrintGCDetails -XX:MaxDirectMemorySize=5m
这个异常出现的步骤就是,我们不断的像list中插入String对象,直到启动GC回收
/**
* GC 回收超时
* JVM参数配置: -Xms10m -Xmx10m -XX:+PrintGCDetails -XX:MaxDirectMemorySize=5m
*/
public class GCOverheadLimitDemo {
public static void main(String[] args) {
int i = 0;
List<String> list = new ArrayList<>();
try {
while(true) {
list.add(String.valueOf(++i).intern());
}
} catch (Exception e) {
System.out.println("***************i:" + i);
e.printStackTrace();
throw e;
} finally {
}
}
}
运行结果
[Full GC (Ergonomics) [PSYoungGen: 2047K->2047K(2560K)] [ParOldGen: 7106K->7106K(7168K)] 9154K->9154K(9728K), [Metaspace: 3504K->3504K(1056768K)], 0.0311093 secs] [Times: user=0.13 sys=0.00, real=0.03 secs]
[Full GC (Ergonomics) [PSYoungGen: 2047K->0K(2560K)] [ParOldGen: 7136K->667K(7168K)] 9184K->667K(9728K), [Metaspace: 3540K->3540K(1056768K)], 0.0058093 secs] [Times: user=0.00 sys=0.00, real=0.01 secs]
Heap
PSYoungGen total 2560K, used 114K [0x00000000ffd00000, 0x0000000100000000, 0x0000000100000000)
eden space 2048K, 5% used [0x00000000ffd00000,0x00000000ffd1c878,0x00000000fff00000)
from space 512K, 0% used [0x00000000fff80000,0x00000000fff80000,0x0000000100000000)
to space 512K, 0% used [0x00000000fff00000,0x00000000fff00000,0x00000000fff80000)
ParOldGen total 7168K, used 667K [0x00000000ff600000, 0x00000000ffd00000, 0x00000000ffd00000)
object space 7168K, 9% used [0x00000000ff600000,0x00000000ff6a6ff8,0x00000000ffd00000)
Metaspace used 3605K, capacity 4540K, committed 4864K, reserved 1056768K
class space used 399K, capacity 428K, committed 512K, reserved 1048576K
Exception in thread "main" java.lang.OutOfMemoryError: GC overhead limit exceeded
at java.lang.Integer.toString(Integer.java:403)
at java.lang.String.valueOf(String.java:3099)
at com.moxi.interview.study.oom.GCOverheadLimitDemo.main(GCOverheadLimitDemo.java:18)
我们能够看到 多次Full GC,并没有清理出空间,在多次执行GC操作后,就抛出异常 GC overhead limit
Direct buffer memory
Netty + NIO:这是由于NIO引起的
写NIO程序的时候经常会使用ByteBuffer来读取或写入数据,这是一种基于通道(Channel) 与 缓冲区(Buffer)的I/O方式,它可以使用Native 函数库直接分配堆外内存,然后通过一个存储在Java堆里面的DirectByteBuffer对象作为这块内存的引用进行操作。这样能在一些场景中显著提高性能,因为避免了在Java堆和Native堆中来回复制数据。
ByteBuffer.allocate(capability):第一种方式是分配JVM堆内存,属于GC管辖范围,由于需要拷贝所以速度相对较慢
ByteBuffer.allocteDirect(capability):第二种方式是分配OS本地内存,不属于GC管辖范围,由于不需要内存的拷贝,所以速度相对较快
但如果不断分配本地内存,堆内存很少使用,那么JVM就不需要执行GC,DirectByteBuffer对象就不会被回收,这时候怼内存充足,但本地内存可能已经使用光了,再次尝试分配本地内存就会出现OutOfMemoryError,那么程序就奔溃了。
一句话说:本地内存不足,但是堆内存充足的时候,就会出现这个问题
我们使用 -XX:MaxDirectMemorySize=5m 配置能使用的堆外物理内存为5M
-Xms10m -Xmx10m -XX:+PrintGCDetails -XX:MaxDirectMemorySize=5m
然后我们申请一个6M的空间
// 只设置了5M的物理内存使用,但是却分配 6M的空间
ByteBuffer bb = ByteBuffer.allocateDirect(6 * 1024 * 1024);
这个时候,运行就会出现问题了
配置的maxDirectMemory:5.0MB
[GC (System.gc()) [PSYoungGen: 2030K->488K(2560K)] 2030K->796K(9728K), 0.0008326 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[Full GC (System.gc()) [PSYoungGen: 488K->0K(2560K)] [ParOldGen: 308K->712K(7168K)] 796K->712K(9728K), [Metaspace: 3512K->3512K(1056768K)], 0.0052052 secs] [Times: user=0.09 sys=0.00, real=0.00 secs]
Exception in thread "main" java.lang.OutOfMemoryError: Direct buffer memory
at java.nio.Bits.reserveMemory(Bits.java:693)
at java.nio.DirectByteBuffer.<init>(DirectByteBuffer.java:123)
at java.nio.ByteBuffer.allocateDirect(ByteBuffer.java:311)
at com.moxi.interview.study.oom.DIrectBufferMemoryDemo.main(DIrectBufferMemoryDemo.java:19)
unable to create new native thread
不能够创建更多的新的线程了,也就是说创建线程的上限达到了
在高并发场景的时候,会应用到
高并发请求服务器时,经常会出现如下异常java.lang.OutOfMemoryError:unable to create new native thread,准确说该native thread异常与对应的平台有关
导致原因:
- 应用创建了太多线程,一个应用进程创建多个线程,超过系统承载极限
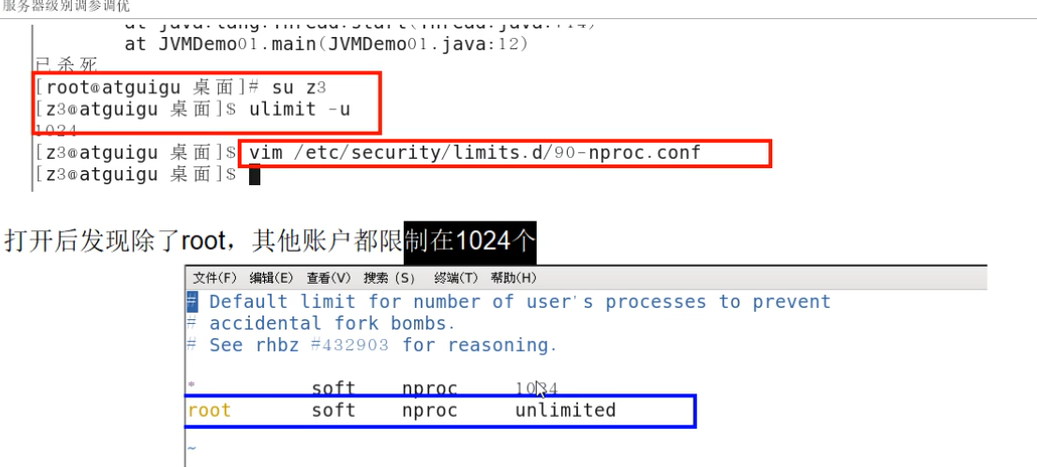
- 服务器并不允许你的应用程序创建这么多线程,linux系统默认运行单个进程可以创建的线程为1024个,如果应用创建超过这个数量,就会报
java.lang.OutOfMemoryError:unable to create new native thread
解决方法:
- 想办法降低你应用程序创建线程的数量,分析应用是否真的需要创建这么多线程,如果不是,改代码将线程数降到最低
- 对于有的应用,确实需要创建很多线程,远超过linux系统默认1024个线程限制,可以通过修改linux服务器配置,扩大linux默认限制
/**
* 无法创建更多的线程
*/
public class UnableCreateNewThreadDemo {
public static void main(String[] args) {
for (int i = 0; ; i++) {
System.out.println("************** i = " + i);
new Thread(() -> {
try {
TimeUnit.SECONDS.sleep(Integer.MAX_VALUE);
} catch (InterruptedException e) {
e.printStackTrace();
}
}, String.valueOf(i)).start();
}
}
}
这个时候,就会出现下列的错误,线程数大概在 900多个
Exception in thread "main" java.lang.OutOfMemoryError: unable to cerate new native thread
如何查看线程数
ulimit -u
服务器级别调参调优:
Metaspace
元空间内存不足,Matespace元空间应用的是本地内存
-XX:MetaspaceSize 的初始化大小为20M
元空间是什么
元空间就是我们的方法区,存放的是类模板,类信息,常量池等
Metaspace是方法区HotSpot中的实现,它与持久代最大的区别在于:Metaspace并不在虚拟内存中,而是使用本地内存,也即在java8中,class metadata(the virtual machines internal presentation of Java class),被存储在叫做Matespace的native memory
永久代(java8后背元空间Metaspace取代了)存放了以下信息:
- 虚拟机加载的类信息
- 常量池
- 静态变量
- 即时编译后的代码
模拟Metaspace空间溢出,我们不断生成类 往元空间里灌输,类占据的空间总会超过Metaspace指定的空间大小
代码
在模拟异常生成时候,因为初始化的元空间为20M,因此我们使用JVM参数调整元空间的大小,为了更好的效果
-XX:MetaspaceSize=8m -XX:MaxMetaspaceSize=8m
代码如下:
/**
* 元空间溢出
*/
public class MetaspaceOutOfMemoryDemo {
// 静态类
static class OOMTest {
}
public static void main(final String[] args) {
// 模拟计数多少次以后发生异常
int i =0;
try {
while (true) {
i++;
// 使用Spring的动态字节码技术
Enhancer enhancer = new Enhancer();
enhancer.setSuperclass(OOMTest.class);
enhancer.setUseCache(false);
enhancer.setCallback(new MethodInterceptor() {
@Override
public Object intercept(Object o, Method method, Object[] objects, MethodProxy methodProxy) throws Throwable {
return methodProxy.invokeSuper(o, args);
}
});
}
} catch (Exception e) {
System.out.println("发生异常的次数:" + i);
e.printStackTrace();
} finally {
}
}
}
会出现以下错误:
发生异常的次数: 201
java.lang.OutOfMemoryError:Metaspace
Linux诊断原因
命令集合
整机:top,查看整机系统性能
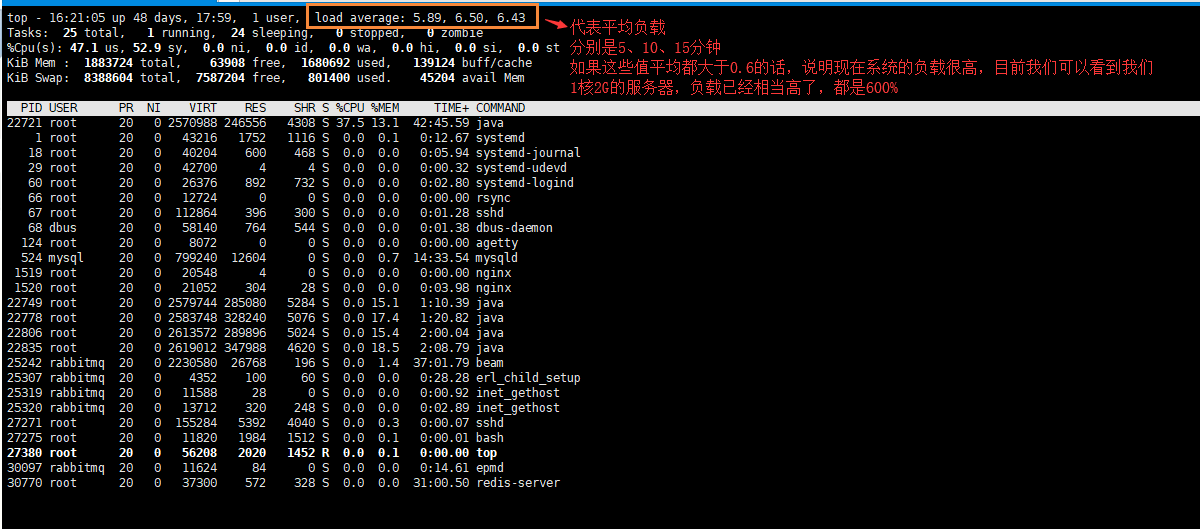
使用top命令的话,重点关注的是 %CPU、%MEM 、load average 三个指标
在这个命令下,按1的话,可以看到每个CPU的占用情况
uptime:系统性能命令的精简版
CPU:vmstat
- 查看CPU(包含但是不限于)
- 查看额外
- 查看所有CPU核信息:mpstat -P ALL 2
- 每个进程使用CPU的用量分解信息:pidstat -u 1 -p 进程编号
命令格式:vmstat -n 2 3

一般vmstat工具的使用是通过两个数字参数来完成的,第一个参数是采样的时间间隔数(单位秒),第二个参数是采样的次数
procs
r:运行和等待的CPU时间片的进程数,原则上1核的CPU的运行队列不要超过2,整个系统的运行队列不超过总核数的2倍,否则代表系统压力过大,我们看蘑菇博客测试服务器,能发现都超过了2,说明现在压力过大
b:等待资源的进程数,比如正在等待磁盘I/O、网络I/O等
cpu
us:用户进程消耗CPU时间百分比,us值高,用户进程消耗CPU时间多,如果长期大于50%,优化程序
sy:内核进程消耗的CPU时间百分比

us + sy 参考值为80%,如果us + sy 大于80%,说明可能存在CPU不足,从上面的图片可以看出,us + sy还没有超过百分80,因此说明蘑菇博客的CPU消耗不是很高
id:处于空闲的CPU百分比
wa:系统等待IO的CPU时间百分比
st:来自于一个虚拟机偷取的CPU时间比
内存:free
- 应用程序可用内存数:free -m
- 查看额外:
pidstat -p 进程号 -r 采样间隔秒数
- 查看额外:
- 应用程序可用内存/系统物理内存 > 70% 内存充足
- 应用程序可用内存/系统物理内存 < 20% 内存不足,需要增加内存
- 20% < 应用程序可用内存/系统物理内存 < 70%,表示内存基本够用
free -h:以人类能看懂的方式查看物理内存

free -m:以MB为单位,查看物理内存

free -g:以GB为单位,查看物理内存
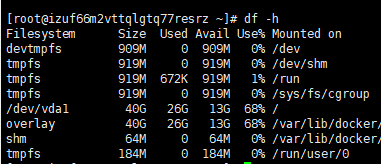
硬盘:df
格式:df -h / (-h:human,表示以人类能看到的方式换算)
- 硬盘IO:iostat
系统慢有两种原因引起的,一个是CPU高,一个是大量IO操作
性能评估,格式:iostat -xdk 2 3
查看额外:pidstat -d 采样间隔秒数 -p 进程号
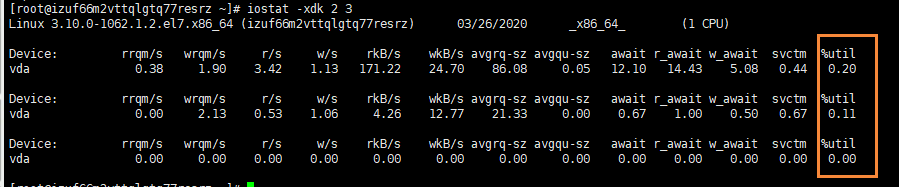
磁盘块设备分布:
rkB /s:每秒读取数据量kB;
wkB/s:每秒写入数据量kB;
svctm I/O:请求的平均服务时间,单位毫秒
await I/O:请求的平均等待时间,单位毫秒,值越小,性能越好
util:一秒钟有百分几的时间用于I/O操作。接近100%时,表示磁盘带宽跑满,需要优化程序或者增加磁盘;
rkB/s,wkB/s根据系统应用不同会有不同的值,但有规律遵循:长期、超大数据读写,肯定不正常,需要优化程序读取。
svctm的值与await的值很接近,表示几乎没有I/O等待,磁盘性能好,如果await的值远高于svctm的值,则表示I/O队列等待太长,需要优化程序或更换更快磁盘
网络IO:ifstat
- 默认本地没有,下载ifstat
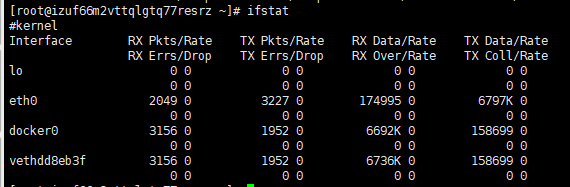
生产环境服务器变慢,诊断思路和性能评估 ⭐️
记一次印象深刻的故障?
结合Linux 和 JDK命令一起分析,步骤如下
-
使用top命令找出CPU占比最高的
-
ps -ef 或者 jps 进一步定位,得知是一个怎么样的后台程序出的问题
-
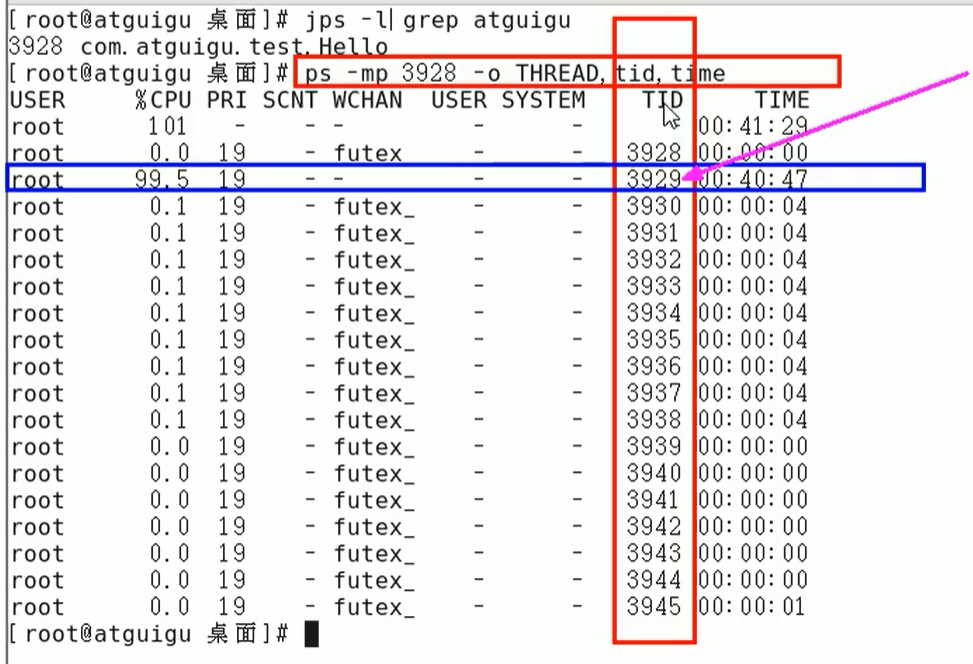
定位到具体线程或者代码
- ps -mp 进程 -o THREAD,tid,time
- 参数解释
- -m:显示所有的线程
- -p:pid进程使用CPU的时间
- -o:该参数后是用户自定义格式
-
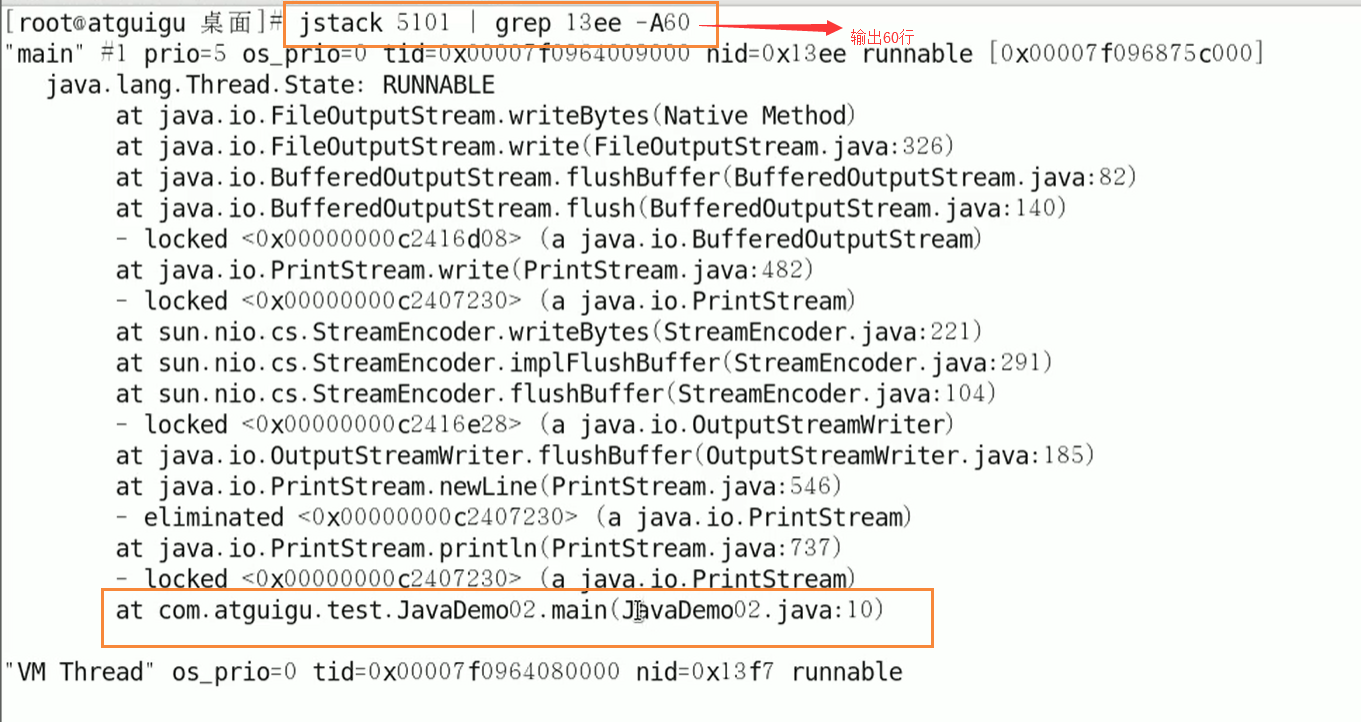
将需要的线程ID转换为16进制格式(英文小写格式)
- printf “%x\n” 有问题的线程ID
-
jstack 进程ID grep tid(16进制线程ID小写英文) -A60 精准定位到错误的地方
既已览卷至此,何不品评一二: