MySQL常用语句整理
MySQL常用语句整理
数据库操作
查看所有数据库
show databases;
使用数据库
use 数据库名;
查看当前使用的数据库
select databases();
创建数据库
create database 数据库名 charset=utf8;
删除数据库
drop database 数据库名;
数据表操作
查看当前数据中所有表
show tables;
查看表结构
desc 表名
创建表
-- PRIMARY KEY(one or more columns)
create table 表名(
column1 datatype,
column2 datatype,
)
-- 创建学生表
create table students(
id int unsigned primary key auto_increment not null,
name varchar(20) default '',
age tinyint unsigned defalut 0,
height decimal(5,2), -- 最大5位数字,其中两位小数的数字类型
gender enum('男','女','保密'),
class_id int unsigned defalut 0
)
mysql的数据类型
-
整数类型:BIT、BOOL、TINY INT、SMALL INT、MEDIUM INT、 INT、 BIG INT
-
浮点数类型:FLOAT、DOUBLE、DECIMAL
-
字符串类型:CHAR、VARCHAR、TINY TEXT、TEXT、MEDIUM TEXT、LONGTEXT、TINY BLOB、BLOB、MEDIUM BLOB、LONG BLOB
-
日期类型:Date、DateTime、TimeStamp、Time、Year
-
其他数据类型:BINARY、VARBINARY、ENUM、SET、Geometry、Point、MultiPoint、LineString、MultiLineString、Polygon、GeometryCollection等
数据类型的属性
| MySQL关键字 | 含义 |
|---|---|
| NULL | 数据列可包含NULL值 |
| NOT NULL | 数据列不允许包含NULL值 |
| DEFAULT | 默认值 |
| PRIMARY KEY | 主键 |
| AUTO_INCREMENT | 自动递增,适用于整数类型 |
| UNSIGNED | 无符号 |
| CHARACTER SET name | 指定一个字符集 |
修改表
-- 添加字段
alter table 表名 add 字段名 类型;
-- 修改字段
alter table 表名 modify 字段名 类型及约束;
-- 修改字段且重命名
alter table 表名 change 原字段名 新字段名 类型及约束;
-- 删除字段
alter table 表名 drop 字段名;
删除表
drop table 表名;
查看表的创建语句
show create table 表名;
增删改查
查询
基本使用
-- 查询所有列
select * from 表名;
-- 查询指定列,可以使用as为列或表指定别名
select 列1,列2,... from 表名;
-- 消除重复行
select distinct 列1,... from 表名;
条件
-- 使用where子句对表中的数据筛选,where后面支持 比较运算符/逻辑运算符/模糊查询/范围查询/空判断
select * from 表名 where 条件;
-- 比较运算符
select * from students where id > 3;
-- 逻辑运算符
select * from students where id > 3 and gender=0;
-- 模糊查询 %表示任意多个任意字符 _表示一个任意字符
select * from students where name like '黄%';
-- 范围查询
select * from students where id in(1,3,8);
-- 空判断;判非空is not null
select * from students where height is null;
排序
-- 将行数据按照列1进行排序,如果某些行列1的值相同时,则按照列2排序,以此类推
-- 默认按照列值从小到大排列(asc)
-- asc从小到大排列,即升序
-- desc从大到小排序,即降序
select * from 表名 order by 列1 asc/desc [,列2 asc|desc,...]
-- 查询学生信息,按名称升序
select * from students order by name;
-- 显示所有的学生信息,先按照年龄从大-->小排序,当年龄相同时 按照身高从高-->矮排序
select * from students order by age desc,height desc;
聚合函数
-- 总数 count(*)表示计算总行数,括号中写星与列名,结果是相同的
-- 查询学生总数
select count(*) from students;
-- 最大值 max(列)表示求此列的最大值
-- 查询女生的编号最大值
select max(id) from students where gender=2;
-- 最小值 min(列)表示求此列的最小值
-- 查询未删除的学生最小编号
select min(id) from students where is_delete=0;
-- 求和 sum(列)表示求此列的和
-- 查询男生的总年龄
select sum(age) from students where gender=1;
-- 平均值 avg(列)表示求此列的平均值
-- 查询未删除女生的编号平均值
select avg(id) from students where is_delete=0 and gender=2;
分组
-- group by的含义:将查询结果按照1个或多个字段进行分组,字段值相同的为一组
-- group by可用于单个字段分组,也可用于多个字段分组
select gender from students group by gender;
-- group by + group_concat()
-- group_concat(字段名)可以作为一个输出字段来使用,
-- 表示分组之后,根据分组结果,使用group_concat()来放置每一组的某字段的值的集合
select gender,GROUP_CONCAT(name) from students group by gender;
-- group by + 集合函数
-- 通过group_concat()的启发,我们既然可以统计出每个分组的某字段的值的集合,那么我们也可以通过集合函数来对这个 值的集合 做一些操作
select gender,avg(age) from students group by gender; -- 分别统计性别为男/女的人年龄平均值
-- group by + having
-- having 条件表达式:用来分组查询后指定一些条件来输出查询结果
-- having作用和where一样,但having只能用于group by
select gender,count(*) from students group by gender having count(*)>2;
-- group by + with rollup
-- with rollup的作用是:在最后新增一行,来记录当前列里所有记录的总和
select gender,count(*) from students group by gender with rollup;
分页
-- 获取部分行
-- 从start开始,获取count条数据
select * from 表名 limit start,count;
-- 查询前3行男生信息
select * from students where gender=1 limit 0,3;
-- 已知:每页显示m条数据,当前显示第n页;求第n页的数据
select * from students where is_delete=0 limit (n-1)*m,m;
连接查询
-- 当查询结果的列来源于多张表时,需要将多张表连接成一个大的数据集,再选择合适的列返回
-- 内连接查询:查询的结果为两个表匹配到的数据
-- 右连接查询:查询的结果为两个表匹配到的数据,右表特有的数据,对于左表中不存在的数据使用null填充
-- 左连接查询:查询的结果为两个表匹配到的数据,左表特有的数据,对于右表中不存在的数据使用null填充
select * from 表1 inner/left/right join 表2 on 表1.列 = 表2.列
-- 使用内连接查询班级表与学生表
select * from students inner join classes on students.cls_id = classes.id;
-- 使用左连接查询班级表与学生表
select * from students as s left join classes as c on s.cls_id = c.id;
-- 使用右连接查询班级表与学生表
select * from students as s right join classes as c on s.cls_id = c.id;
-- 查询学生姓名及班级名称
select s.name,c.name from students as s inner join classes as c on s.cls_id = c.id;
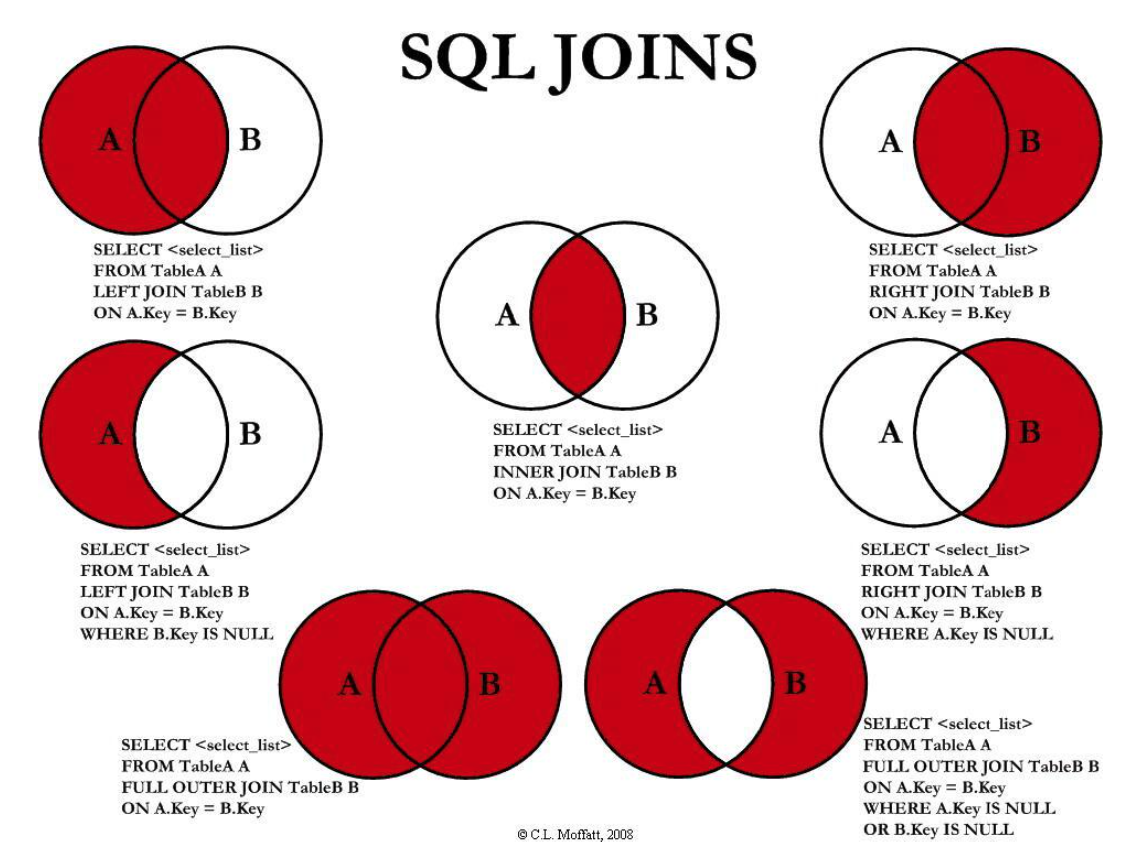
其中mysql不支持外连接,6 = 1 union 2; 7 = 4 union 5。
自关联
-- 自关联: 表中的某一列,关联了这个表中的另外一列,但是它们的业务逻辑含义是不一样的,城市信息的pid引用的是省信息的id
子查询
-- 子查询: 在一个 select 语句中,嵌入了另外一个 select 语句, 那么被嵌入的 select 语句称之为子查询语句
-- 主查询和子查询的关系
---- 子查询是嵌入到主查询中
---- 子查询是辅助主查询的,要么充当条件,要么充当数据源
---- 子查询是可以独立存在的语句,是一条完整的 select 语句
-- 标量子查询
-- 查询班级学生的平均身高
select * from students where age > (select avg(age) from students);
-- 列级子查询
-- in关键字的使用: 主查询 where 条件 in (列子查询)
-- 查询还有学生所在班的班级名字
select name from classes where id in (select cls_id from students);
-- 行级子查询
-- 查找班级年龄最大,身高最高的学生
-- 行元素: 将多个字段合成一个行元素,在行级子查询中会使用到行元素
select * from students where (height,age) = (select max(height),max(age) from students);
总结
关键字执行顺序
- from 表名
- where ….
- group by …
- select distinct *
- having …
- order by …
- limit start,count
增加
mysql中常用的三种插入数据的语句:
- insert into表示插入数据,数据库会检查主键,如果出现重复会报错;
- replace into表示插入替换数据,需求表中有PrimaryKey,或者unique索引,如果数据库已经存在数据,则用新数据替换,如果没有数据效果则和insert into一样;
- insert ignore表示,如果中已经存在相同的记录,则忽略当前新数据;
-- 主键列是自动增长,但是在全列插入时需要占位,通常使用0或者 default 或者 null 来占位,插入成功后以实际数据为准
insert into 表名 values(...);
insert into students values(0,’张三‘,1,'浙江','2016-1-2');
-- 全列插入:值的顺序与表中字段的顺序对应
insert into 表名(列1,...) values(值1,...);
insert into students(name,hometown,birthday) values('黄蓉','桃花岛','2016-3-2');
-- 全列多行插入:值的顺序与给出的列顺序对应
insert into 表名(列1,...) values(值1,...),(值1,...)...;
insert into students(name) values('张三'),('杨过'),('小龙女');
修改
update 表名 set 列1=值1,列2=值2... where 条件;
update students set gender=0,hometown='北京' where id=5;
删除
delete from 表名 where 条件
delete from students where id=5;
-- 逻辑删除,本质就是修改操作
update students set isdelete=1 where id=1;
索引
索引是一种特殊的文件(InnoDB数据表上的索引是表空间的一个组成部分),它们包含着对数据表里所有记录的引用指针。
更通俗的说,数据库索引好比是一本书前面的目录,能加快数据库的查询速度。
-- 查看索引
show index from 表名;
-- 创建索引 在执行CREATE TABLE语句时可以创建索引,也可以单独用CREATE INDEX或ALTER TABLE来为表增加索引。
-- CREATE INDEX可对表增加普通索引或UNIQUE索引。
CREATE INDEX index_name ON table_name (`column_list`)
CREATE UNIQUE INDEX index_name ON table_name (`column_list`)
-- ALTER TABLE用来创建普通索引、UNIQUE索引或PRIMARY KEY索引。
ALTER TABLE table_name ADD INDEX index_name (`column_list`)
ALTER TABLE table_name ADD UNIQUE (`column_list`)
ALTER TABLE table_name ADD PRIMARY KEY (`column_list`)
-- 创建复合索引
ALTER TABLE table_name ADD INDEX index_name (`col1`,`col2`,`col3`);
-- 删除索引
drop index 索引名称 on 表名;
在MySQL中创建表的时候,可以直接创建索引。基本的语法格式如下:
- UNIQUE:可选。表示索引为唯一性索引。
- FULLTEXT;可选。表示索引为全文索引。
- SPATIAL:可选。表示索引为空间索引。
- INDEX和KEY:用于指定字段为索引,两者选择其中之一就可以了,作用是一样的。
- 索引名:可选。给创建的索引取一个新名称。
- 字段名1:指定索引对应的字段的名称,该字段必须是前面定义好的字段。
- 长度:可选。指索引的长度,必须是字符串类型才可以使用。
- ASC:可选。表示升序排列。
- DESC:可选。表示降序排列。
CREATE TABLE 表名(字段名 数据类型 [完整性约束条件],
[UNIQUE | FULLTEXT | SPATIAL] INDEX | KEY
[索引名](字段名1 [(长度)] [ASC | DESC])
);
备份/恢复
# 备份
mysqldump –uroot –p 数据库名 > backup.sql;
# 按提示输入mysql的密码
# 恢复
mysql -uroot –p 新数据库名 < backup.sql
视图
为什么要有视图?
对于复杂的查询,往往是有多个数据表进行关联查询而得到,如果数据库因为需求等原因发生了改变,为了保证查询出来的数据与之前相同,则需要在多个地方进行修改,维护起来非常麻烦
视图是什么
通俗的讲,视图就是一条SELECT语句执行后返回的结果集。所以我们在创建视图的时候,主要的工作就落在创建这条SQL查询语句上。
视图是对若干张基本表的引用,一张虚表,查询语句执行的结果,不存储具体的数据(基本表数据发生了改变,视图也会跟着改变);
方便操作,特别是查询操作,减少复杂的SQL语句,增强可读性;
-- 定义视图 建议以v_开头
create view 视图名称 as select语句;
-- 查看视图 查看表会将所有的视图也列出来
show tables;
-- 使用视图 视图的用途就是查询
select * from v_stu_score;
-- 删除视图
drop view 视图名称;
事务
-- 开启事务
begin;/start transaction;
-- 提交事务
commit;
-- 回滚事务
rollback;
既已览卷至此,何不品评一二: