操作系统 内存分配
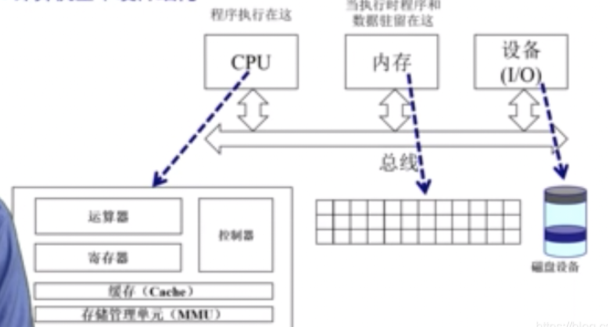
计算机体系结构及内存分层体系
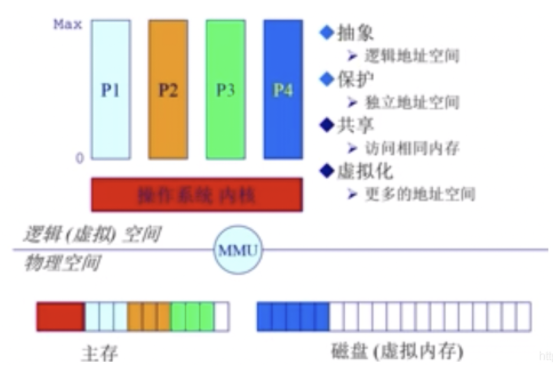
操作系统在内存管理要完成的目标:
- 抽象:逻辑地址空间
- 保护:独立地址空间
- 共享:访问相同内存
- 虚拟化:更多的地址空间
操作系统实现内存管理目标的手段:
- 程序重定位
- 分段
- 分页
- 虚拟内存
- 按需分页虚拟内存
地址空间与地址生成
地址空间的定义
物理地址空间:硬件支持的地址空间
逻辑地址空间:一个运行的程序所拥有的内存范围
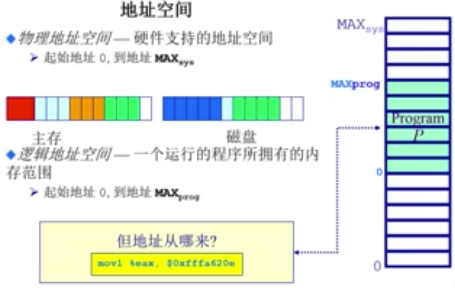
地址空间的生成
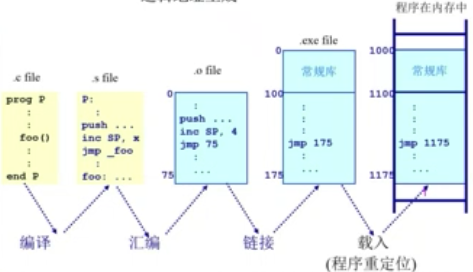
应用程序的逻辑地址是如何映射到物理地址
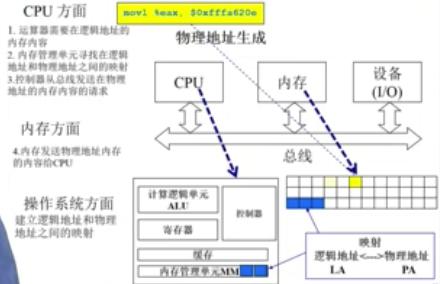
CPU方面:
- 运算器ALU需要在逻辑地址的内存内容(CPU要逻辑地址)
- 内存管理单元MMU寻找在逻辑地址和物理地址之间的映射(然后MMU找逻辑和物理地址的关系)
- 控制器从总线发送在物理地址的内存内容的请求(关系找到后,去找对应物理地址)
内存方面:
- 内存发送物理地址内存内容给CPU(物理地址找到了,给CPU)
操作系统方面:
- 建立逻辑地址和物理地址之间的映射(确保程序不相互干扰)
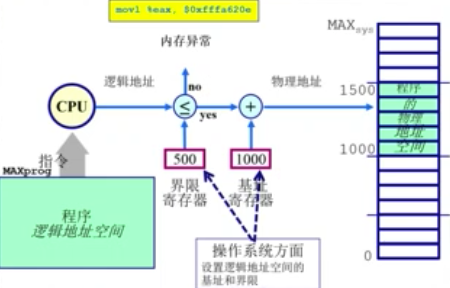
地址安全检查
CPU要执行某条指令时,要去查找该map,如果要访问的逻辑地址不满足区域的限制则产生内存异常。
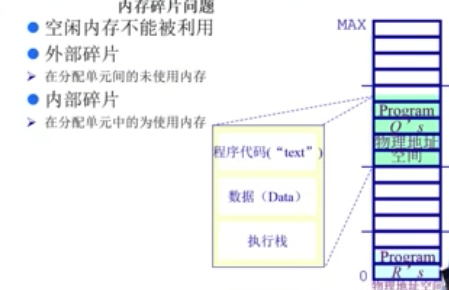
连续内存分配
内存碎片问题
- 空闲内存不能被利用
- 外部碎片:在分配单元间的未使用内存
- 内部碎片:在分配单元中的未使用内存
分区的动态分配
- 当一个程序准许运行在内存中时,分配一个连续的区间
- 分配一个连续的内存区间给运行的程序以访问数据

分区的动态分配策略
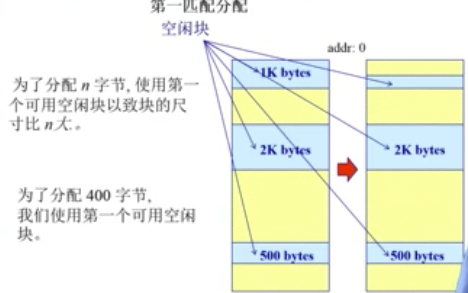
首次适配
现在想分配n字节,从低地址开始找,碰到的第一个空间比n大的空闲块就使用它。
要想实现首次分配,需要满足以下条件:
- 需要存在一个按地址排序的空闲块列表
- 分配需要找一个合适的分区
- 重分配需要检查,看看自由分区能不能与相邻的空闲分区合并(形成更大的空闲块)
优缺点:
- 优点
- 简单
- 易于产生更大的空闲块,向着地址空间的结尾
- 缺点
- 外部碎片的问题会加剧
- 不确定性
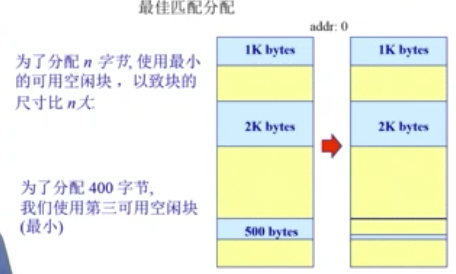
最佳适配
为了分配n字节,使用最小的可用空闲块,以致块的尺寸比n大。
目的:避免分割大的空闲块;最小化外部碎片产生的尺寸。
要想实现最佳分配,需要满足以下条件:
- 按尺寸排列的空闲列表
- 分配需要寻找一个合适的分区
- 重分配需要搜索和合并于相邻的空闲分区
优缺点:
- 优点
- 大部分分配是小尺寸时很有效;简单
- 缺点
- 外部碎片;重分配慢;易产生很多没用的微小碎片。
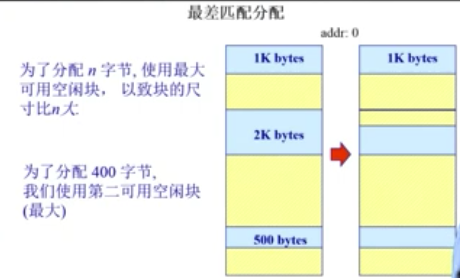
最差适配
为了分配n字节,使用最大的可用空闲块,以致块的尺寸比n大。
目的:避免太多的微小碎片
要想实现最差分配,需要满足以下条件:
- 按尺寸排列的空闲列表
- 分配很快(获得最大的分区)
- 重分配需要合并于相邻的空闲分区,若有,然后调整空闲块列表
优缺点:
- 优点
- 假如分配时是中等尺寸效果最好
- 缺点
- 重分配慢;外部碎片;易于破碎大的空闲块以至大分区不能被分割
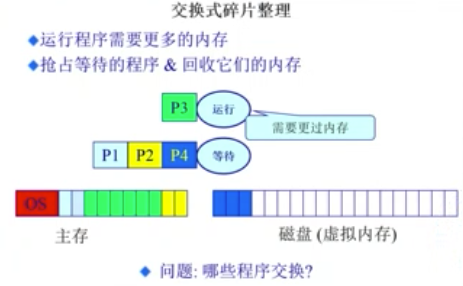
压缩式与交换式碎片整理
压缩式碎片整理(紧致)
- 重制程序以合并孔洞
- 要求所有程序是 动态可重置的
- 问题:何时重置;开销。

交换式碎片整理
- 运行程序需要更多的内存
- 抢占等待的程序或回收它们的内存(把暂时不用的内容挪到磁盘里)
非连续式内存分配
非连续内存分配的原因
连续内存分配的缺点:
- 分配给一个程序的物理内存是连续的
- 内存利用率低
- 有外碎片/内碎片问题
非连续内存分配的优点:
- 分配给一个程序的物理内存是非连续的
- 更好的内存利用和管理
- 允许共享代码和数据(共享库等)
- 支持动态加载和动态链接
非连续内存分配的缺点:
- 如何建立虚拟地址和物理地址之间的转换
- 软件方案(开销大)
- 硬件方案
- 分段Segmentation
- 分页Paging
分段
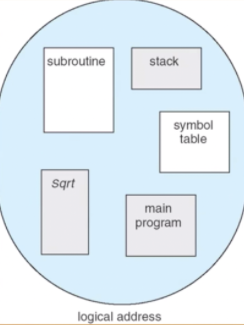
程序的分段地址空间
逻辑地址空间是连续的,物理地址是离散的。
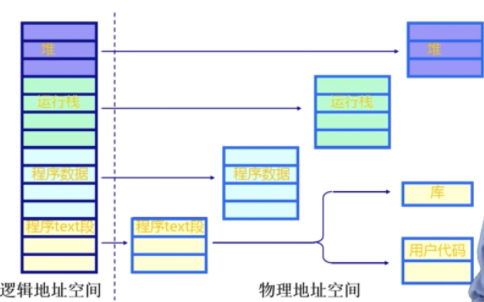
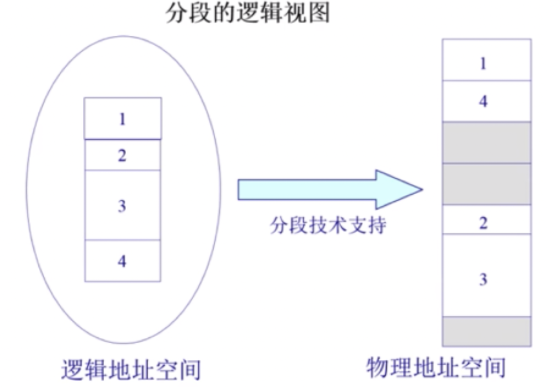
分段寻址的方案
段访问机制
一个段指一个“内存块”,是一个逻辑地址空间。程序根据段访问机制访问内存地址需要一个二维的二元组(s段号,addr端内偏移)
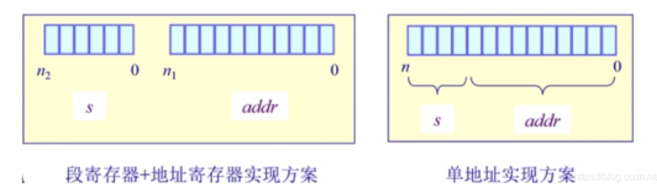
段访问机制的硬件实现方案:
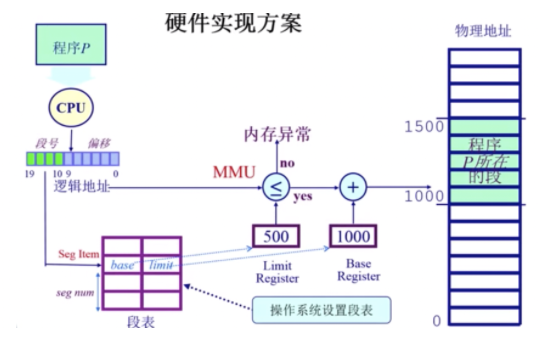
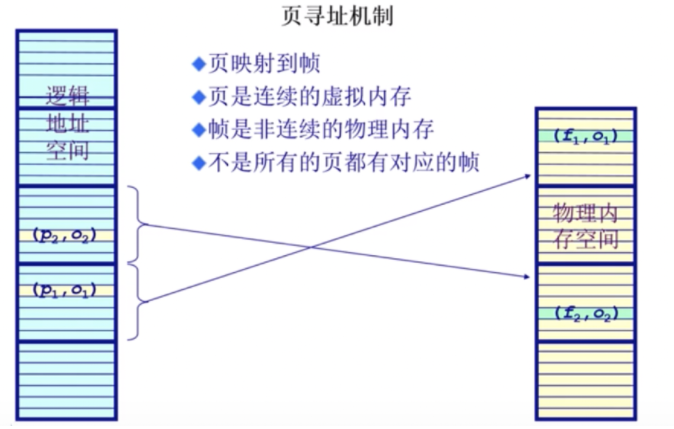
分页
分页地址空间
- 划分物理内存至固定大小的帧,大小是2的幂,e.g.512,4096,8192。
- 划分逻辑地址空间至相同大小的页,大小是2的幂,e.g.512,4096,8192。
- 建立方案:转换逻辑地址为物理地址(pages to frames)
- 页表Page Table
- MMU/TLB(快表)
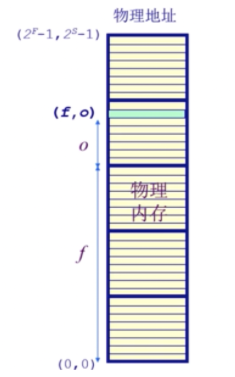
物理地址部分:页帧
页帧:物理内存被分割为大小相等的帧(物理地址部分)。
一个内存的物理地址是一个二元组(f,o):
- f:帧号(它是F位的,因此意味着一共$2^F$个帧);
- o:帧内偏移(它是S位的,因此意味着每帧有$2^S$字节);
- 物理地址=$2^S ✖️ f + o$。
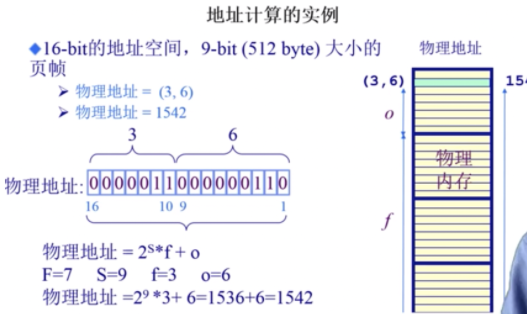
通过一个实例来加深对这个概念的理解:
首先有一个物理内存地址(3,6),帧号是3,它是7位的,说明一共能有$2^7$个帧,这个帧是其中的第3个; 帧内偏移是6,他是9位的,说明一个帧里可以有$2^9$个字节,当前地址是在这个帧里的第6个字节; 因此,它的物理地址是$3 * 2^9 + 6$。 通过这个例子,可以发现 页帧号 的作用就是通过一个二元组能够找到一个物理地址。
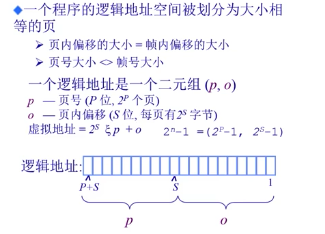
逻辑地址部分:页
页:一个程序的逻辑地址空间被划分为大小相等的页(逻辑地址部分)
- (逻辑地址的)页内偏移量=(物理地址的)帧内偏移量
- (逻辑地址的)页号大小可能不等于(物理地址的)帧号大小
通过这个例子,可以发现 页号 的作用就是通过一个二元组能够找到一个逻辑地址。页号和帧号不是相等的。
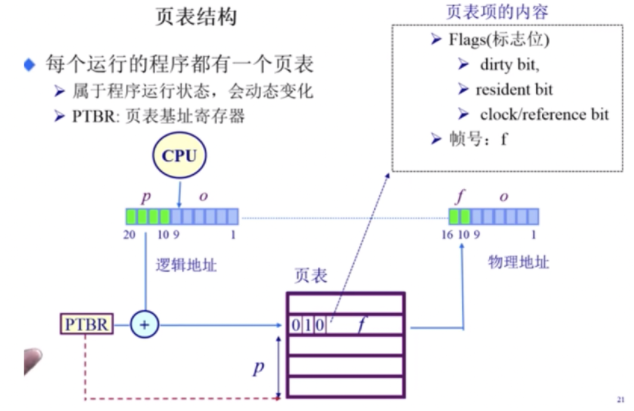
页寻址机制的实现
页表实际上就是一个大的数组hash表。它的index是页号,对应的value是页帧号,首先根据逻辑地址计算得到一个 页号,也就是index,再在页表中找到对应的 页帧号,最后根据 页帧号 计算得到物理地址;由于他们的页/帧内偏移相等,所以页表不需要保存这个数据。通过这种方式能够根据逻辑地址找到对应的物理地址。除此之外,还有一些flags标志位。
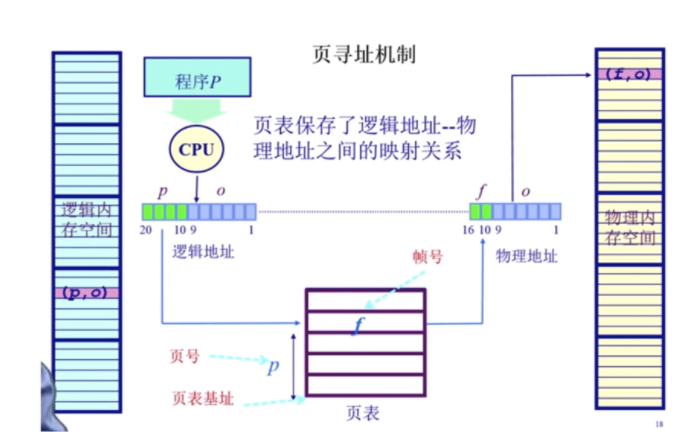
页表TLB
页表概述
通过标志位来判断当前页号的性质。
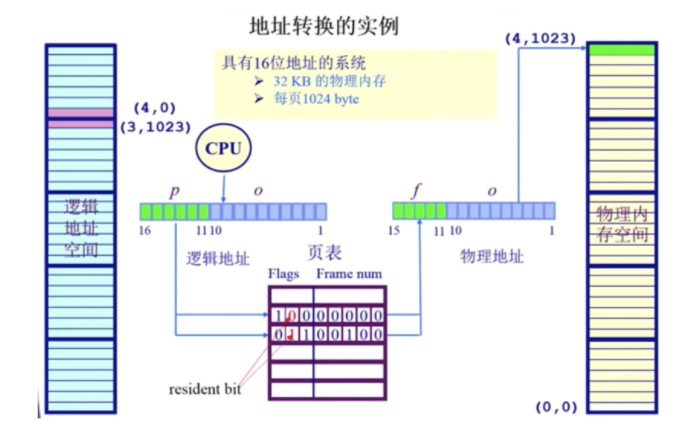
地址转换实例:
下图中,逻辑地址空间是16位64kB,物理地址空间是15位32kB,并不是对等的,但是一页和一帧的大小是一样的,都是10位1kB。
- 逻辑地址(4,0),页号4对应的二进制是100,它的位置对应着flags。根据上图,可知它的dirty bit是1,resident bit是0,clock/reference是0;因此可以知道逻辑地址(4,0)在物理地址中实际是不存在的。如果CPU访问这个逻辑地址会抛出一个内存访问异常;
- 逻辑地址(3,1034),页号3对应的二进制是011,它的位置(也就是页号的位置)对应着flags。根据上图,可知它的dirty bit是0,resident bit是1,clock/reference是1;因此可以知道逻辑地址(3,1034)在物理地址中存在。再复习一下,页表里存放的是什么。因为由于逻辑地址的页内偏移和物理地址的帧内偏移是一样的,所以页表不需要保存偏移。根据页表,页号3对应的页帧号是4,再加上它们的偏移量相等,所以逻辑地址(3,1034)对应的物理地址是(4,1023)。
- 这个页表是由操作系统维护。
分页机制的性能问题
空间代价和时间代价。
- 访问一个内存单元需要2次内存访问:一次获取页表项;一次是访问数据。
- 页表可能会非常大(页表的长度等于2^页号位数)
- 举例,64位机器,如果一页是1024KB,那么页表是多大? 假如页号是n位的,那么页表的长度等于$2^ n$,一页是1024KB,所以页内偏移是10位,一个逻辑地址的长度等于计算机位数,也就是64位,因此剩下的54位是留给页号的;因此页表的长度是 $2^{54}$,明显CPU装不下。
- 一个程序一个页表,n个程序n个页表,就更大了。
- CPU装不下,只能装在内存里;如果这样,需要访问2次内存,一次访问页表,一次访问程序。
解决办法:
- 缓存caching
- 间接访问indirecion
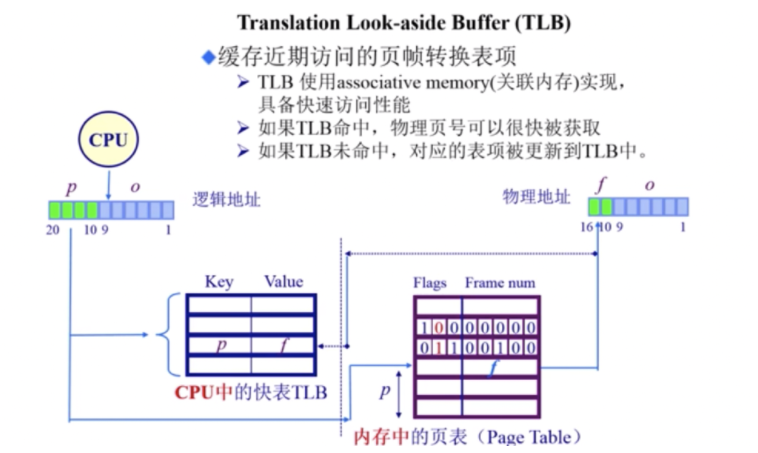
转换后备缓冲区/快表TLB
如何优化页表的时间开销问题,解决办法是 缓存。
TLB实际上是CPU的MMU内存管理单元保存的一段缓存,这段缓存保存的内容是 页表 的一部分,是经常访问到的那部分页表,其余不常用的页表内容保存在内存中。 TLB未命中,也叫TLB miss,这种情况比较少见,因为一页很大,32位系统一页是4K,如果采用局部性原理,那么访问4k次才会遇到一次TLB miss。
页表-二级/多级页表
如何优化页表的空间开销问题,解决方法是 多级页表。 虽然增加了内存访问次数和开销,但是节省了保存页表的空间(时间换空间,然后在通过TLB来减少时间消耗)。
逻辑地址中,页号部分分成了两个部分,p1和p2。
- p1存放着二级页表的起始地址,p2的作用就是之前的p。
- p1找二级页表,p2找页,o找地址。
- 这里体现了二级页表的另一个好处,就是p1对应的位置是flags,假如说resident bit是0,那么整个二级页表都不用在内存中保存,这个是一级页表无法实现的!
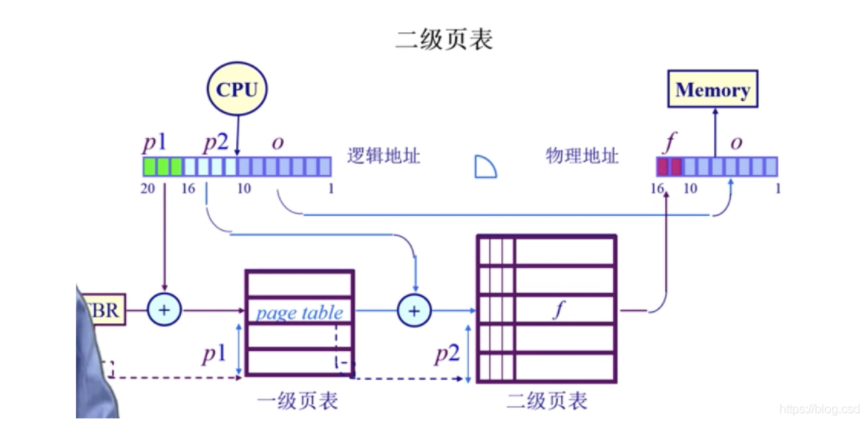
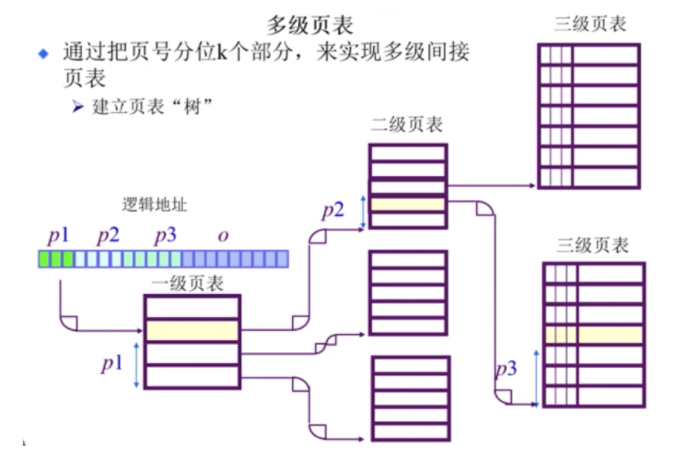
多级页表,如64位系统采用5级页表。
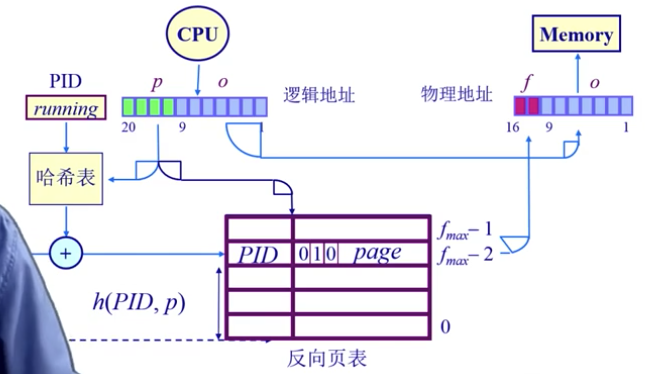
页表-反向页表
页表来表示物理地址(页帧)号,而不是之前的逻辑地址(页号),能够减少页表尺寸,但是给映射关系的建立带来点困难。
传统页表的缺点
- 对于大地址空间,前向映射页表变得繁琐(例如64位系统采用5级页表)。
- 逻辑地址空间增长速度快于物理地址空间,所以反向页表,也就是index是物理地址,value是逻辑地址,它的大小会小于传统页表。
反向页表的实现
基于页寄存器的方案
每一个帧和一个寄存器关联,它包括:
- residence bit:此帧是否被占用;
- occupier:对应的页号p;
- protection bit:保护位;
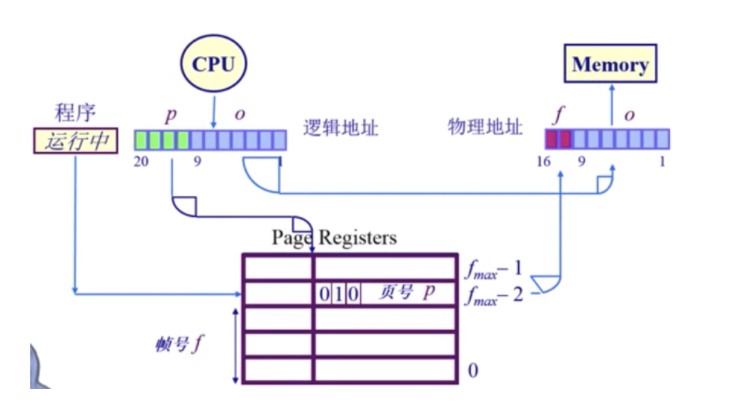
举一个例子:
物理内存大小:4096 * 4096 KB = 16 MB
页面大小:4064 bytes = 4 KB
页帧数: 4K
页寄存器使用的空间(假设是8 bytes的register):8 * 4096 = 32 KB
页寄存器的额外开销:32 KB / 16 MB = 0.2%
虚拟内存的大小:任意
可以看出内存开销很小。
页寄存器的优缺点:
- 优点
- 转换表的大小相对于物理内存来说很小;
- 转换表的大小跟逻辑地址空间的大小无关。
- 缺点
- 需要的信息对调了,如何根据帧号找到页号呢;
- 需要在反向页表里去找想要的页号。
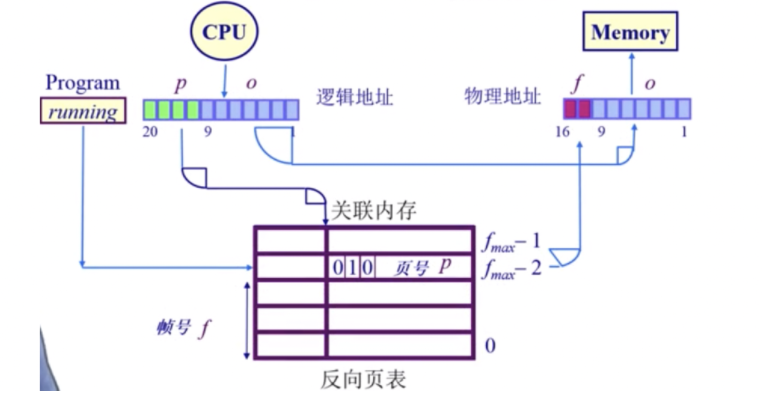
基于关联内存的方案
开销太大:
- 如果帧数较少,页寄存器可以被放置在关联内存中;
- 在关联内存中查找逻辑页号,成功了,帧号就被提取出来;失败了,页错误异常page fault。
- 限制这种方案的因素包括,大量的关联内存非常昂贵(难以在单个时钟周期内完成;耗电)。
基于哈希查找的方案
该方法可以缓解映射的开销,可能导致一个key出现2个以上的value对应(哈希碰撞)。 这种方式仍然需要把反向页表放在内存中,做hash计算的时候还需要在内存中取数,仍然需要多次访问内存。

既已览卷至此,何不品评一二: