Spring Data JPA
JPA
/Users/silince/Develop/MagicDontTouch/IdeaProjects/Java
1. ORM思想
主要目的:操作实体类就相当于操作数据库表,不再重点关注sql语句 建立两个映射关系:
- 实体类和表的映射关系
- 实体类中属性和表中字段的映射关系
实现了ORM思想的框架:mybatis,hibernate
2. hibernate框架介绍
Hibernate是一个开放源代码的对象关系映射框架,
-
对JDBC进行了非常轻量级的对象封装,
-
将POJO与数据库表建立映射关系,是一个全自动的ORM框架
3. JPA or Mybatis ?
现在一个场景,你手头有个项目
- 原始JDBC对接数据库。发现自己组装对象太痛苦,而且还需要自己建表。累死个人。有个框架能自动组装对象,还能自动建表就好了。
- SpringDataJpa框架。然后你发现了Springdatajpa,你仿佛打开了新世界的大门,原来的简单的增删改查都不用写了,直接继承到。而且数据库表也不用建了,直接自动生成。原来一天的数据库操作的代码,现在完全不用写,简单的条件查询,一条语句就搞定。爽到飞起。但是随着项目体量的增大,用户数量激增。表结构慢慢复杂起来,对查询性能也有了要求。然后你在想,有没有能便于优化数据库语句性能的解决方案啊。jpa优化性能并不是那么便利。
- mybatis:然后你发现了mybatis,你发现你打开了又一扇大门。直接映射返回对象,前台所需要的数据库建个DTO类就行,多表关联的数据也可以一个DTO接收所有数据。根据条件组装各种SQL,简直是爽爆了。
- 换回jpa:你改给人做项目了,甲方爸爸经常换,公司经常强制要求数据库从mysql换成oracle,但是业务比以前简单了。你发现mybatis因为sql纯手写,依赖于数据库。不便于换数据源。你想起了不依赖数据源的jpa,你把原有项目简化了一下后,换回了jpa,你发现现在可以服务于多个甲方爸爸的数据源,并且不需要改查询,换个配置全搞定。
- 领悟:回想自己在多个框架跌爬滚打,明白了技术是服务于业务的,没有绝对“银弹”的技术,只有适合当前业务的技术。
上面故事讲的有点长了,来说下自己的理解。
其实现在市面上对比这里啊框架,我觉得他们大多都是在描述技术上的区别。我的看法是
- jpq是面向对象的思想,一个对象就是一个表,强化的是你对这个表的控制。jpa继承的那么多表约束注解也证明了jpa对这个数据库对象控制很注重。
- mybatis则是面向sql,你的结果完全来源于sql,而对象这个东西只是用来接收sql带来的结果集。你的一切操作都是围绕sql,包括动态根据条件决定sql语句等。mybatis并不那么注重对象的概念。只要能接收到数据就好。
面向sql就更利于优化,因为sql可以优化的点太多了。面向对象就更利于移植,因为数据对象不依赖于数据源。俩系统的用户分页语句可能不一样,但是属性都是那么几个。
4.JPA的基本操作
JPA规范:实现jpa规范,内部是由接口和抽象类组成
JPA基本操作案例:是客户的相关操作(增删改查)
i. 搭建环境的过程
-
创建maven工程导入坐标
-
需要配置jpa的核心配置文件
-
位置:配置到类路径下的一个叫做 META-INF 的文件夹下
-
命名:persistence.xml
-
-
编写客户的实体类
-
配置实体类和表,类中属性和表中字段的映射关系
-
保存客户到数据库中
ii. 完成基本CRUD案例
persist : 保存 merge : 更新 remove : 删除 find/getRefrence : 根据id查询
iii. jpql查询
sql:查询的是表和表中的字段 jpql:查询的是实体类和类中的属性
jpql和sql语句的语法相似
- 查询全部
- 分页查询
- 统计查询
- 条件查询
- 排序
jpa操作的操作步骤
1.加载配置文件创建实体管理器工厂
Persisitence:静态方法(根据持久化单元名称创建实体管理器工厂)
createEntityMnagerFactory(持久化单元名称)
作用:创建实体管理器工厂
2.根据实体管理器工厂,创建实体管理器
EntityManagerFactory :获取EntityManager对象
方法:createEntityManager
* 内部维护的很多的内容
内部维护了数据库信息,
维护了缓存信息
维护了所有的实体管理器对象
再创建EntityManagerFactory的过程中会根据配置创建数据库表
* EntityManagerFactory的创建过程比较浪费资源
特点:线程安全的对象
多个线程访问同一个EntityManagerFactory不会有线程安全问题
* 如何解决EntityManagerFactory的创建过程浪费资源(耗时)的问题?
思路:创建一个公共的EntityManagerFactory的对象
* 静态代码块的形式创建EntityManagerFactory
3.创建事务对象,开启事务
EntityManager对象:实体类管理器
beginTransaction : 创建事务对象
presist : 保存
merge : 更新
remove : 删除
find/getRefrence : 根据id查询
Transaction 对象 : 事务
begin:开启事务
commit:提交事务
rollback:回滚
4.增删改查操作
5.提交事务
6.释放资源
SpringDataJPA
/Users/silince/Develop/MagicDontTouch/IdeaProjects/Java EE/Spring Data JPA/springdatajpa
1. springDataJpa的概述
Spring Data JPA 是 Spring 基于 ORM 框架、JPA 规范的基础上封装的一套 JPA 应用框架,可使开 发者用极简的代码即可实现对数据库的访问和操作。它提供了包括增删改查等在内的常用功能,且易于扩展,学习并使用 Spring Data JPA 可以极大提高开发效率。
Spring Data JPA 让我们解脱了 DAO 层的操作,基本上所有 CRUD 都可以依赖于它来实现,在实际的 工作工程中,推荐使用 Spring Data JPA + ORM(如:hibernate)完成操作,这样在切换不同的 ORM 框架时提供了极大的方便,同时也使数据库层操作更加简单,方便解耦。
2. springDataJpa的入门操作
案例:客户的基本CRUD
i.搭建环境
- 创建工程导入坐标
- 配置spring的配置文件(配置spring Data jpa的整合)
- 编写实体类(Customer),使用jpa注解配置映射关系
ii.编写一个符合springDataJpa的dao层接口
- 只需要编写dao层接口,不需要编写dao层接口的实现类
- dao层接口规范
- 需要继承两个接口(JpaRepository,JpaSpecificationExecutor)
- 需要提供相应的泛型
JpaRepository<操作的实体类类型,实体类中主键属性的类型>封装了CRUD操作JpaSpecificationExecutor<操作的实体类类型>封装了复杂查询(分页)
findOne(id) :根据id查询
save(customer):保存或者更新(依据:传递的实体类对象中,是否包含id属性)
delete(id) :根据id删除
findAll() : 查询全部
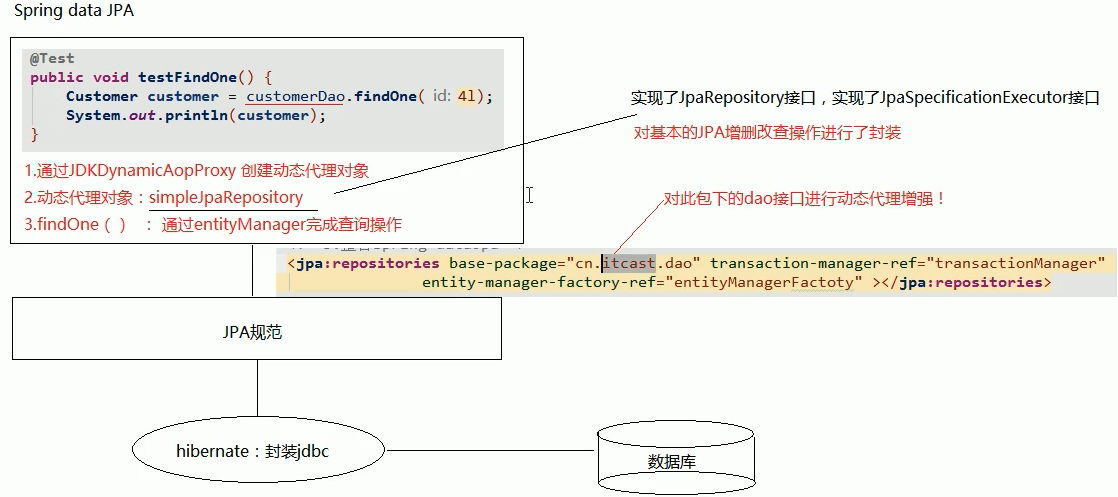
3. springDataJpa的运行过程和原理剖析
- 通过JdkDynamicAopProxy的invoke方法创建了一个动态代理对象
- SimpleJpaRepository当中封装了JPA的操作(借助JPA的api完成数据库的CRUD)
- 通过hibernate完成数据库操作(封装了jdbc)
4. 复杂查询
i. 借助接口中的定义好的方法完成查询
- findOne(id):根据id查询
ii. jpql的查询方式
- 特点:语法或关键字和sql语句类似
- 查询的是类和类中的属性
- 需要将JPQL语句配置到接口方法上
- 特有的查询:需要在dao接口上配置方法
- 在新添加的方法上,使用注解的形式配置jpql查询语句
- 注解 :
@Query
iii. sql语句的查询
- 特有的查询:需要在dao接口上配置方法
- 在新添加的方法上,使用注解的形式配置sql查询语句
- 注解 : @Query
- value :jpql语句/sql语句
- nativeQuery :是否使用本地查询
- false(使用jpql查询)
- true(使用本地查询:sql查询)
iiii.方法名称规则查询
是对jpql查询更加深入的一层封装。我们只需要按赞SpringDataJpa提供的方法名规则定义方法,不需要再去配置jpql语句完成查询。
findBy + 对象中属性的名称(首字母大写)根据属性名称进行完全匹配查询findBy + 对象中属性的名称(首字母大写) + 查询方式(Like/isnull)根据属性名称进行模糊匹配查询findBy + 对象中属性的名称(首字母大写) + and/or 属性名多条件查询
5. Specifications动态查询
/Users/silince/Develop/MagicDontTouch/IdeaProjects/Java EE/Spring Data JPA/jpaspecification
JpaSpecificationExecutor 方法列表
//查询单个对象
T findOne(Specification<T> spec);
//查询列表
List<T> findAll(Specification<T> spec);
//查询全部,分页
//pageable:分页参数
//返回值:分页pageBean(page:是springdatajpa提供的)
Page<T> findAll(Specification<T> spec, Pageable pageable);
//查询列表
//Sort:排序参数
List<T> findAll(Specification<T> spec, Sort sort);
//统计查询
long count(Specification<T> spec);
Specification 自定义我们自己的Specification实现类
- 实现Specification接口(提供范型:查询对象类型)
- 实现toPredicate方法(构造查询条件)
- 需要借助方法参数中的两个参数
- root: 获取需要查询的对象属性
- CriteriaBuilder: 构造条件查询的,内部封装了很多的查询条件[模糊匹配/精准匹配等]
@Test
public void testSpec(){
// 匿名内部类
/* ex: 根据客户名称查询
* 查询条件:
* 1 查询方式: criteriaBuilder对象
* 2 比较的属性名称: root对象
* */
Specification<Customer> spec = new Specification<Customer>() {
@Override
public Predicate toPredicate(Root<Customer> root, CriteriaQuery<?> criteriaQuery, CriteriaBuilder criteriaBuilder) {
//1 获取比较的属性
Path<Object> custName = root.get("custName");
//2 构造查询条件
Predicate predicate = criteriaBuilder.equal(custName, "gakki");// 进行精准的匹配(需要比较的属性名,比较的属性的取值)
return predicate;
}
};
Customer customer = customerDao.findOne(spec);
System.out.println(customer);
}
SpringDataJPA 多表操作
1. 多表之间的关系和操作多表的操作步骤
表关系
一对一
一对多:
一的一方:主表
多的一方:从表
外键:需要再从表上新建一列作为外键,他的取值来源于主表的主键
多对多:
中间表:中间表中最少应该由两个字段组成,这两个字段做为外键指向两张表的主键,又组成了联合主键
讲师对学员:一对多关系
实体类中的关系
包含关系:可以通过实体类中的包含关系描述表关系
继承关系
分析步骤
1.明确表关系
2.确定表关系(描述 外键|中间表)
3.编写实体类,再实体类中描述表关系(包含关系)
4.配置映射关系
2. 完成多表操作
i.一对多操作
案例:客户和联系人的案例(一对多关系)
客户:一家公司
联系人:这家公司的员工
一个客户可以具有多个联系人
一个联系人从属于一家公司
分析步骤
1.明确表关系
一对多关系
2.确定表关系(描述 外键|中间表)
主表:客户表
从表:联系人表
* 再从表上添加外键
3.编写实体类,再实体类中描述表关系(包含关系)
客户:再客户的实体类中包含一个联系人的集合
联系人:在联系人的实体类中包含一个客户的对象
4.配置映射关系
* 使用jpa注解配置一对多映射关系
级联:
操作一个对象的同时操作他的关联对象
级联操作:
1.需要区分操作主体
2.需要在操作主体的实体类上,添加级联属性(需要添加到多表映射关系的注解上)
3.cascade(配置级联)
级联添加,
案例:当我保存一个客户的同时保存联系人
级联删除
案例:当我删除一个客户的同时删除此客户的所有联系人
ii.多对多操作
案例:用户和角色(多对多关系)
用户:
角色:
分析步骤
1.明确表关系
多对多关系
2.确定表关系(描述 外键|中间表)
中间间表
3.编写实体类,再实体类中描述表关系(包含关系)
用户:包含角色的集合
角色:包含用户的集合
4.配置映射关系
iii.多表的查询
1.对象导航查询
查询一个对象的同时,通过此对象查询他的关联对象
案例:客户和联系人
从一方查询多方
* 默认:使用延迟加载(****)
从多方查询一方
* 默认:使用立即加载
既已览卷至此,何不品评一二: